![[-]](/moniwiki/imgs/plugin/arrup.png "[-]")
![[+]](/moniwiki/imgs/plugin/arrdown.png "[+]")
[edit]
1 서브타입과 개체집합의 통합 #
개체집합을 도출하다 보면 일반화(또는 세분화)가 이루어지는 경우가 있다. 예를 들면 고객은 개인과 법인으로 나눌 수 있다. 그러므로 고객은 개체집합이 아니라고 판단할 수도 있다. 그러나 고객은 분명히 개체집합이다. 개인과 법인은 고객의 부분집합일 뿐이다. 개인과 법인의 합집합이 고객이다. 즉, 구분된 부분집합은 교집합이 존재해서는 안 된다. 합쳐서 100이 되어야 한다. 실제로 많은 사람들이 고객, 개인, 법인에 대한 통합의 딜레마에 빠진다. 그것은 기준이 정해져 있지 않기 때문이다. 다음은 서브타입을 고려해야 할 경우이다.
- 두 집합의 교집합이 있고, 두 집합간의 차집합이 존재할 경우
- 두 집합간의 확연히 차이가 나는 속성이 있을 경우
- 특정 집합만 다른 개체집합과 관계를 맺을 경우
| 의미의 희석이란, 의미의 희석은 개체가 통합되면 속성이 계속 추가되어 정의한 개체집합의 정의가 더 넓어지는 것을 의미한다. 즉, 처음에는 토마토였는데 거기에 감자의 유전자를 자꾸 결합시켜서 토마토도 아닌 것이 감자도 아닌 것이 되버리는 것과 같다. 또 다른 비유를 하자면 처음에는 "대한민국 국적을 가진 주민번호를 발급받은 사람"이 정의였는데, 통합하여 집합의 정의가"주민번호와 외국인번호가 있는 국내 거주자"이 된 것과 같다. |
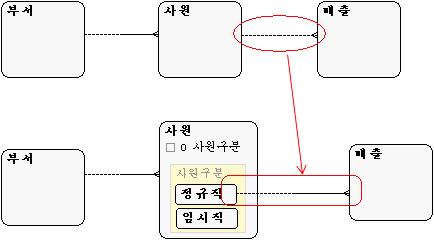
위 그림의 경우 직원은 정규직과 임시직이 있다. 매출은 직원에 의해 일어날 수 있는 비확정적인 관계이지만 정규직만이 매출을 할 수 있다면 관계는 안쪽의 정규직이라는 부분집합과만 관계를 맺게 된다. 이것은 관계의 선택성을 제거한 것이다. 또한 속성들이 통합되어 하나의 개체집합으로 표현된다. 그러면 각 부분집합만이 가지는 속성은 선택적(비확정적)인 속성이 된다. 서브타입으로 내린다면 그 선택적 속성은 필수적 속성으로 바뀌는 것이다. 실제로 모델링에서는 서브타입을 도출한다고 해서 물리적으로 구현된느 테이블이 하나더 생기는 것이 아니다. 지금 단계에서는 그런 것을 생각할 단계가 아니므로 모델을 구체화하기 위해 서브타입을 도출하는 것은 좋은 모델을 만드는 과정이라고 생각하면 된다. 서브타입은 슈퍼타입의 모든 속성, 관계, 식별자가 상속되고, 고유한 속성 또는 관계를 적어도 하나 이상을 가진다. 실제로 슈퍼타입에는 분류속성을 가지게 되는데, 분류속성은 반드시 Mandatory 속성이다. 물리적으로는 Not Null 컬럼이 되는 것이다.
대부분의 통합은 개체집합을 정의하면서 이루어지기 마련이다. 대부분의 통합은 잘못된 개체집합의 정의로 통합이 이루어진다. 또한 도메인이 같거나 역할, 개념이 같다면 통합하는 것이 모델의 복잡성도 줄이고, 단순화된다. 예를들어 어떤 회사내에 도서관이 있는데 그 도서관은 사원들에게만 개방하는 도서관이다. 그런데도 불구하고 사원, 회원이란 개체집합이 존재한다. 그러므로 사원 = 회원이므로 이것은 통합의 대상이다. 이러한 문제는 예를 들어 몇줄로 설명했지만 많은 사이트에서 나타나는 문제이다. 물론 기존의 시스템도 있고, 신시스템도 있어 여기저기에 데이터가 중복되어 있는 경우도 많이 있다. 하지만 이렇게 데이터가 고립되어 있다는 것은 매우큰 문제다. 대부분의 개체통합은 이러한 것이다. 다만 서브타입들을 따로 떨어뜨려 놓을 것인가 아니면 분리할 것인가에 대한 문제가 있다. 서브타입도 관계를 가지고 맺고, 슈퍼타입도 관계를 맺을 수 있고, 한 부분집합만이 가지는 속성이 있을 수 있으나 대부분은 역시 통합이 유리하다. 다만 의미가 희석되지 않는 범위내에서 통합하는 것이 중요하다. 물론 따로 분리하는 것도 좋다. 실제로 구현될 때 따로 떨어지게 된다면 테이블의 크기도 줄어들고, 관리면에서도 심플해질 수도 있다. 중요한 것은 서브타입은 부분집합이지 서로 다른 개체집합이 아니라는 것이다.
[edit]
2 코드의 통합 방법 #
코드의 통합 방법은 3가지 정도다. 일반화된 솔루션은 아니지만 필자의 경험상으로 여러 경우에 나누어 코드의 통합방법에 대해서 정리를 해보았다. 다음과 같은 3가지 모델로 제시한다. 말그대로 코드 통합의 방법이지 코드개체에 대한 설계를 이렇게 하라는 것이 아니다. 통합의 이슈가 발생할 경우에 적용을 고려해 보라.
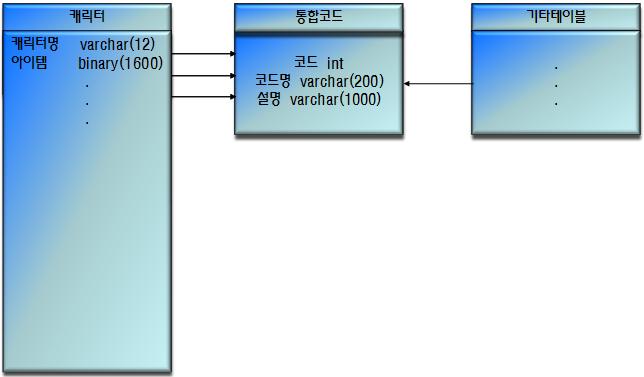
통합코드
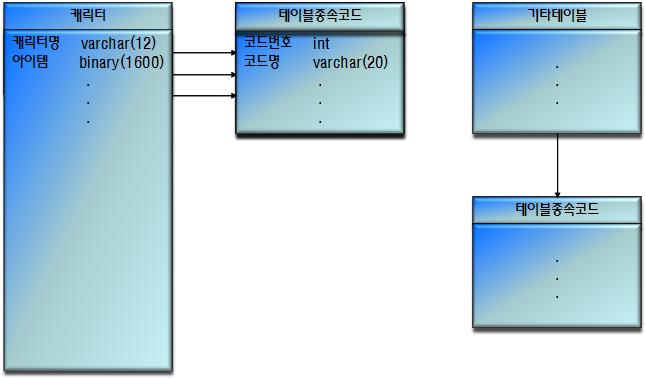
테이블 종속코드
도메인 종속코드
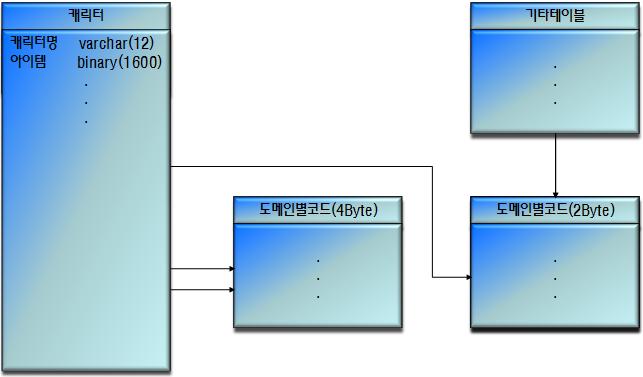
각 코드 통합방식의 장/단점 및 적용방안

[edit]
3 Bill-Of-Material(BOM) 관계 #
순환 관계는 BOM 관계를 포함하는 전체집합으로 보면 되겠다. 즉, BOM 관계는 순환관계의 특별한 경우로 순환관계가 다:다의 관계를 이루고 있을 때 BOM 관계라고 한다. 그러나 우습게도 책마다 그냥 순환관계와 BOM 관계를 특별히 구분 짓고 있는 책도 있고, 그렇지 않은 책도 있다. 여기서는 BOM관계를 순환관계의 다:다 관계로 보겠다. 대부분의 BOM 관계는 제품을 만드는 공장 같은 곳에서 많이 볼 수 있다. 마찬가지로 다:다의 관계므로 해소를 해주면 된다.
실제로 상품과 상품의 다:다 관계이므로 다른 다:다 관계처럼 해소시켜 주면 된다.

다:다 관계를 해소하면 다음과 같이 된다.

그러나 하나의 제품이라는 개체집합이 중복되어 나타났으므로 이를 없애주면 아래와 같이 도출될 수 있다.
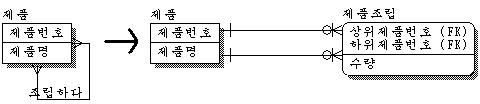
[edit]
4 관계의 통합 #
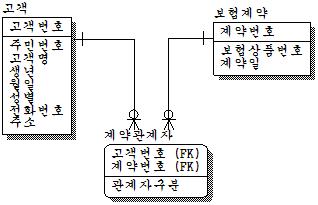
개체집합과 개체집합간의 관계는 반드시 하나의 관계로만 이루어지지는 않는다. 다중 관계의 예로 보험회사의 고객과 보험계약간의 관계가 있다.
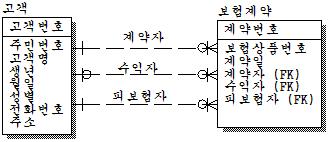
보험계약을 하면 계약자가 있어야 하고, 반드시 계약 상품이 있어야 한다. 그러므로 보험계약은 중심개체집합이며, 계약자와 피보험자는 반드시 있어야 하며, 수익자는 있을 수도 있고, 없을 수도 있다. 실제로 E-R WIN이란 툴로 표현한 것인데 논리모델이므로 FK이 이미 나와 있다. 즉, FK는 관계이다.
실제로 관계모델에서는 위와 같은 형태의 릴레이션이 나타날 수 있다. 중요한 것은 계약자, 피보험자, 수익자가 여러명인가 한명인가가 문제이다. 또한 관계가 하나 추가시 테이블의 구조 변경이 일어나야 한다. 또한 이렇게 계속 컬럼이 추가되다보면 인덱스의 증가 가능성이 높다. 그러므로 유연한 모델을 만들기 위해서 관계를 통합하는 것이 좋다. 위 관계들을 통합하면 어떻게 모델이 변할까?
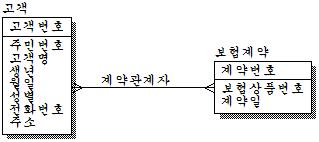
계약자도 고객이고, 피보험자도 고객이고, 수익도 고객이다. 최소한 카디날리티는 3:N이므로 다:다의 관계가 된다. 명칭은 적당히 Domain Level을 높이면 된다.
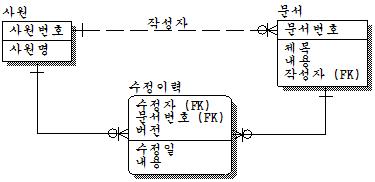
다른 경우를 살펴보자. 다음은 사원과 문서간의 관계를 나타내고 있다.
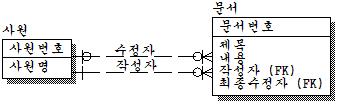
문서는 반드시 작성자가 있어야 하며, 수정자는 없을 수도 있다. 또한 사원은 문서를 작성할 수도 있으며, 수정할 수도 있다.
이것도 관계명을 적절히 부여하고, 하나의 관계로 통합할 수 있다. 그러나 작성자는 최초 작성자를 뜻하며, 수정자는 최종 수정자를 뜻한다. 간혹 관계가 여러 개 도출되어 중복이라고 생각하는데 중복인지 아닌지는 일단 카디널리티만 봐도 틀리므로 당연히 위와 같은 관계는 중복이 아니다. 문제는 다중 관계를 통합하느냐 아니면 그대로 놔두느냐의 문제이다. 필자라면 위와 같은 경우라면 적절하다고 판단이 된다. 변화의 예상이 안되고, 관계의 수도 적으므로 인덱스 증가에 대한 오버헤드도 적다. 관계를 통합하면 하나의 개체집합이 더 도출되므로 복잡해 질 수 있다. 그러나 언제 문서가 작성되었으며, 수정자와 수정한 날짜, 수정한 내용에 대한 버전관리(이력관리)가 필요하다면 또 틀려진다. 만약 아래의 아래와 같이 했다면 문서의 이력관리라고는 볼 수 없다.
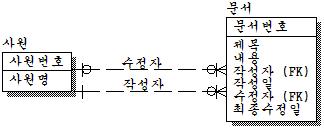
문서의 버전에 대한 관리를 위해서는 아래와 같이 모델이 변경되어야 한다.