![[-]](/moniwiki/imgs/plugin/arrup.png "[-]")
![[+]](/moniwiki/imgs/plugin/arrdown.png "[+]")
이제 설계가 실제 구현 시 어떤 영향을 끼치는지를 살펴보도록 하겠다. 다음의 사례를 보고 인덱스 생성과 설계상의 문제에 대한 이해를 돕도록 해보자. 독자들도 필자의 솔루션을 읽어보지 말고 아래의 문제에 대해서 고민해보기 바란다. 항상 느끼는 것이지만 데이터베이스는 답을 알고 나면 매우 쉽다. '왜 저 생각을 못했지?' 하고 끝나지 말기를 바란다. 중요한 것은 데이터를 바라보는 새로운 눈을 가지는 것이다.
[edit]
1 사례1: Clustered Index의 생성 #
프로젝트 진행 단계 중 물리설계 단계에 DBA는 다음과 같은 테이블에 인덱스를 생성하려 한다. DBMS는 MSSQL Server이다.
문제의도
이 문제는 Clustered Index와 Non-Clustered Index를 알고 있어야 하는 문제이다. (나온 용어는 그것 뿐이니까..) 그러나 이 문제를 낸 의도는 설계가 물리적인 설계와 구현에 미치는 영향을 설명하기 위함이다.
고객ID 가입일 입금일 기타컬럼들.. ------ -------- -------- ---------- yasi 20050516 20050516 .. temp 20050401 20050407 ..DBA는 고민에 빠졌다. 가입일에 Clustered Index를 생성하자니 입금일이 마음에 걸리고, 입금일에 Non-Clustered Index를 생성하자니 가입일과 입금일에 접근 횟수는 비슷하다고 판단되었다. 이러한 고민은 DBA가 Non-Clustered Index를 생성하는 컬럼은을 이용한 SQL의 성능에 문제가 될 것이라는 발상에서 나온 것이다. 이 딜레마를 어떻게 해결해야 할까? 단, 위와 같은 테이블 구조라면 고객ID는 Unique하다.
이 문제는 Clustered Index와 Non-Clustered Index를 알고 있어야 하는 문제이다. (나온 용어는 그것 뿐이니까..) 그러나 이 문제를 낸 의도는 설계가 물리적인 설계와 구현에 미치는 영향을 설명하기 위함이다.
솔루션
사실 애매모호한 문제다. 여기서 가입이 한 조직과 고객이 처음으로 관계를 가지는 것이라면 가입일은 고객의 속성이 될 수 있다. 하지만 고객이 이미 존재하는 상태에서 동호회와 같은 조직내의 더 작은 조직에 가입한다는 의미라면 가입은 고객의 속성이 아닌 동호회와 고객간의 관계가 된다. 입금일에 대한 정의도 모호하다. 고객만이 입금하라는 법은 없다. 가입을 함으로써 조직에서 고객에게 입금해 줄 수도 있다. 단지 알 수 있는 것은 고객ID가 위 테이블 구조에서 Unique라고 했으니 입금은 1회만 가능하다는 것이다. 필자가 문제를 제시했지만 문제 자체가 문제. 여기에서는 고객ID, 가입일, 입금일 이 3가지 속성을 다음과 같이 정의하도록 하자. 나머니 기타컬럼들은 없다고 가정하자. (기타컬럼은 문제의도와는 관계 없다.)
사실 애매모호한 문제다. 여기서 가입이 한 조직과 고객이 처음으로 관계를 가지는 것이라면 가입일은 고객의 속성이 될 수 있다. 하지만 고객이 이미 존재하는 상태에서 동호회와 같은 조직내의 더 작은 조직에 가입한다는 의미라면 가입은 고객의 속성이 아닌 동호회와 고객간의 관계가 된다. 입금일에 대한 정의도 모호하다. 고객만이 입금하라는 법은 없다. 가입을 함으로써 조직에서 고객에게 입금해 줄 수도 있다. 단지 알 수 있는 것은 고객ID가 위 테이블 구조에서 Unique라고 했으니 입금은 1회만 가능하다는 것이다. 필자가 문제를 제시했지만 문제 자체가 문제. 여기에서는 고객ID, 가입일, 입금일 이 3가지 속성을 다음과 같이 정의하도록 하자. 나머니 기타컬럼들은 없다고 가정하자. (기타컬럼은 문제의도와는 관계 없다.)
- 고객ID:각각의 고객을 유일하게 구분하는 설계속성
- 가입일: 고객과 조직이 처음 관계를 가진 날짜
- 입금일: 고객이 조직에게 1만 원을 입금한 날짜
| 고객ID | 발생일자 | 발생구분 |
여기서 발생구분은 가입 또는 입금일 것이다...만약 가입, 입금, 추가입금과 같이 더 많은 구분을 원한다면 발생구분에 대한 값만 변경되면 된다. 테이블의 구조가 변하는 것이 아니라 값이 변화하는 것이다. 실제로 발생한 인스턴스의 예를 보면...
고객ID 발생일자 발생구분 ------- -------- ------- yasi 20041231 가입 yasi 20050105 입금 sckim 20050109 가입
위와 같은 구현이 될 것이다. 그러면 문제에서 고민했던 Clustered Index와 Non-Clustered Index에 대한 고민은 사라지게 된다. 그럼 인덱스 설계는 어떻게 해야 할까? 이것은 쿼리패턴과 데이터의 발생량, 분포를 알아야 정확히 결정 할 수 있다. 고객ID가 Unique하다는 것을 알았으므로 같은 고객ID는 최대 2개가 된다. 그러므로 후보키는 (고객ID, 발생구분) 또는 (고객ID, 발생일자)가 된다. 대표성으로 따진다면 (고객ID, 발생구분)이 기본키가 될 것이다. 가입과 입금이 서브타입이 될 것이기 때문이다. 물리적인 구현까지 생각한다면 기본키가 어떤 후보키가 되건 순서가 매우 중요하게 된다.
만약 가입과 입금과 관련된 쿼리수가 비슷한 횟수이고, 날짜 검색 기간이 비교적 짧다면 발생일자에만 클러스터드 인덱스를 생성하면 될 것이다. 하지만 발생구분 + 발생일자(또는 발생일자 + 발생구분)로 인덱스를 생성하는 것인 더 유리한지 따져봐야 한다. 인덱스 유지보수 비용과 쿼리비용(Filter비용) 중 어떤 것이 더 많이 필요로 하는지만 알게 되면 복합인덱스냐 단일인덱스냐의 결정문제는 해결된다. 현실적으로 가입Row수:입금Row수 비율을 따져 봤을 때에 비율이 많이 차이 난다면 단일 발생일자로 단일 인덱스를 생성하는 것이 유리할 것이다. 경우에 따라서는 테이블을 수직분할 하는 것이 훨씬 유리할 수도 있다. 예를 들어 고객ID, 입금일은 삽입연산이고, 입금일에 갱신연산이 집중된다면 수직분할이 동시성 문제를 해결할 수도 있다. 물론 '기타컬럼들'에 따라서 수직분할이 아닌 자연스러운 정규화가 될 수도 있다.
참고
또 다른 관점
또 다른 관점에서 테이블을 살펴보자. 테이블을 보면 가입일과 입금일이 있다. 만약 고객 중 가입을 한 행위를 한 고객과 입금을 한 고객이 틀릴 수도 있다면 어떨까? (물론 가입을 한 고객이 입금도 할 수 있을 수 있다.) 만약 그렇다면 문제의 테이블은 절대 '고객'이 될 수 없다. 적어도 입금자라는 순환관계가 하나 더 있어야 고객이라고 볼 수 있을 것이다.[1] 만약 테이블이 고객이 아니라면 아마도 병렬관계(가입자, 입금자, 추천자등..)가 되거나[2] 이 병렬관계를 통합한 형태가 될 것이다. 물론 병렬관계도 고객이 조직과의 관계를 가졌다(일반적으로 회원가입)는 가정하에서이다. 고객에게 돈을 입금받는데 꼭 가입을 해야만 돈을 받을 수 있다는 업무규칙 자체는 참으로 어리석다. 가입을 받는 것도 어려운데 돈을 받으려고 가입 후 입금하라고 할 수는 없는 노릇이다. 아마도 이렇게 따져 들어가면 애초에 정의를 애매모호하게 했기 때문에 모든 경우의 수에 대해서 이야기해야 하므로 이쯤에서 멈추도록 하겠다. 다음은 이해를 돕기 위한 그림이다.
| 만약 복합인덱스로 결정이 되었고, 쿼리 조건에서 발생구분을 반드시 명시한다면 인덱스에 참여하는 컬럼들의 순서는 반드시 발생구분 + 발생일자가 되어야 할 것이다. 왜냐하면 발생일자는 검색하지 않아도 발생구분에 대한 조회는 반드시 일어나야 날짜에 대한 의미가 있기 때문이다. 발생구분이 왜 인덱스를 포함하는 컬럼이 되어야 하는지는 의아해 할 수도 있다. 그러나 모델이 통합되면서 해당 고객에 대한 로우는 최소 2개 또는 그 이상이 되어야 하기 때문이다. 그러므로 구분을 인덱스 포함시켜 결합인덱스로 생성하면 선택도가 좋아진다. 또한 인덱스가 클러스터드 인덱스를 생성하게 되면 발생구분별로 발생일자를 정렬되어 검색에 더욱 유리해 질 것이다. |
또 다른 관점
또 다른 관점에서 테이블을 살펴보자. 테이블을 보면 가입일과 입금일이 있다. 만약 고객 중 가입을 한 행위를 한 고객과 입금을 한 고객이 틀릴 수도 있다면 어떨까? (물론 가입을 한 고객이 입금도 할 수 있을 수 있다.) 만약 그렇다면 문제의 테이블은 절대 '고객'이 될 수 없다. 적어도 입금자라는 순환관계가 하나 더 있어야 고객이라고 볼 수 있을 것이다.[1] 만약 테이블이 고객이 아니라면 아마도 병렬관계(가입자, 입금자, 추천자등..)가 되거나[2] 이 병렬관계를 통합한 형태가 될 것이다. 물론 병렬관계도 고객이 조직과의 관계를 가졌다(일반적으로 회원가입)는 가정하에서이다. 고객에게 돈을 입금받는데 꼭 가입을 해야만 돈을 받을 수 있다는 업무규칙 자체는 참으로 어리석다. 가입을 받는 것도 어려운데 돈을 받으려고 가입 후 입금하라고 할 수는 없는 노릇이다. 아마도 이렇게 따져 들어가면 애초에 정의를 애매모호하게 했기 때문에 모든 경우의 수에 대해서 이야기해야 하므로 이쯤에서 멈추도록 하겠다. 다음은 이해를 돕기 위한 그림이다.
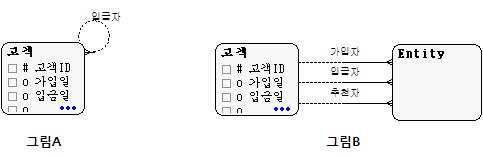
결론
퀴즈처럼 고민했던 어떤 컬럼에 Clustered Index를 생성할 것인가에 대한 고민은 설계상으로 해결되었다. 또한 하나의 테이블 인덱스를 더 적게 생성했으므로 관리해야 할 객체 수도 줄였다. 또한 업무가 변화하여 가입, 입금 이외에 다른 업무가 발생하여도 유연하게 대처할 수 있게 된 구조를 가지게 된다. 하지만 애매모호한 정의로 많은 혼란을 가져다 준 문제였다. 모호한 정의가 가져다주는 위험성을 알려주기 위함이었다. 관계는 엔터티 집합간의 관련이 생기게 되는 업무적인 이유이다. 이러한 관계에 대한 명확한 정의가 이루어지지 않고는 완벽한 모델과 설계가 이루어졌다고 할 수 없는 노릇이다.
퀴즈처럼 고민했던 어떤 컬럼에 Clustered Index를 생성할 것인가에 대한 고민은 설계상으로 해결되었다. 또한 하나의 테이블 인덱스를 더 적게 생성했으므로 관리해야 할 객체 수도 줄였다. 또한 업무가 변화하여 가입, 입금 이외에 다른 업무가 발생하여도 유연하게 대처할 수 있게 된 구조를 가지게 된다. 하지만 애매모호한 정의로 많은 혼란을 가져다 준 문제였다. 모호한 정의가 가져다주는 위험성을 알려주기 위함이었다. 관계는 엔터티 집합간의 관련이 생기게 되는 업무적인 이유이다. 이러한 관계에 대한 명확한 정의가 이루어지지 않고는 완벽한 모델과 설계가 이루어졌다고 할 수 없는 노릇이다.
[edit]
2 사례2: 회원 로그인에 관한 분석 #
설계의 중요성은 아무리 언급을 해도 지나치지 않다. 대부분의 성능은 설계를 잘하면 그에 따른 보답이 있다. 설계가 엉망이라면 성능을 보장할 수 없다. 이제 한가지 예로 회원 로그인에 관한 부분을 살펴보며 설계가 어떤 영향을 끼치지는 살펴본다. 더 구체적인 예들은 데이터베이스 디자인 튜닝 부분에서 다룬다. 먼저 웹에 공개되어 있는 회원관리형태의 소스를 분석해 보았다. 회원관리를 위해서는 데이터베이스나 파일이 필요하다. 여기서는 데이터베이스를 이용하는 방법에 대한 것을 설명하려 한다. 먼저 각각의 회원관리 소스에서 로그인 체크하는 부분에 대한 소스를 살펴 보자. (보안과 관련된 자세한 부분은 생략하겠다.)
위의 소스는 ASP소스인데 대부분의 로그인 하는 부분에서 위와 같은 쿼리를 DB에 던지는 식이였다. 다른 소스는 저장프로시저를 이용하고 있었다. 그 내용은 다음과 같다. 필자의 의견은 위의 솔루션보다는 아래의 것이 훨씬 낫다고 보는 바이다. 왜냐하면 일단 SQL문을 DB서버에 데이터를 전달해야 하는데 저장 프로시저로 캡슐화하여 보안을 강화했고, 또한 전달하는 문자열이 짧기 때문에 네트웍 트래픽도 감소시켰기 때문이다. 또한 DB서버에서는 아래의 소스에서 보는 바와 같이 프로시저 실행결과를 1, 2, 3 중에 하나만 클라이언트로 전달하게 되므로 하나만 역시 네트웍 트래픽도 줄어들었다는 것이다.
참고
| SP를 사용하면 네트웍 트래픽은 실제로 줄어드는 일은 별로 없을 것이다. 왜냐하면 패킷단위(일반적으로 4096 Byte)로 데이터를 주고 받을 것기 때문이다. 만약 소스에서 직접 SQL문을 서버에 던졌을 때에 그 SQL이 한 패킷단위보다 크다면 네트워크 트래픽은 줄어들 것이지만 대부분의 경우 한 패킷단위 크기 만큼 긴 SQL문은 없다. 위에서 이야기한 네트웍 트래픽은 그저 처리량이 줄어들었다는 정도로만 이해해두자. |
CREATE PROCEDURE SP_MEM_LOGIN @M_ID VARCHAR(20), @M_PWD VARCHAR(20) AS BEGIN DECLARE @EXISTS INT DECLARE @PWD VARCHAR(15) IF EXISTS(SELECT M_ID FROM MEM_MAST WHERE M_ID=@M_ID) BEGIN SELECT @PWD=M_PWD FROM MEM_MAST WHERE M_ID=@M_ID IF @PWD <> @M_PWD SELECT @EXISTS=3 ELSE SELECT @EXISTS=1 END ELSE BEGIN SELECT @EXISTS=2 END RETURN @EXISTS END
분석을 해보면 회원의 아이디와 패스워드를 입력받으면 먼저 아이디가 존재하는지 검사하여 아이디가 존재하면 사용자로부터 입력받는 패스워드와 DB에 저장되어 있는 패스워드를 검사하여 만약 입력받은 패스워드와 저장된 패스워드가 다르면 3을 리턴하고 정보가 일치하면 1을 리턴하게 된다. 만약 입력한 아이디가 존재하지 않으면 2를 리턴하게 된다. 한가지 아쉬운 점은 테이블 디자인이다. 다음은 테이블 디자인된 모습이다.
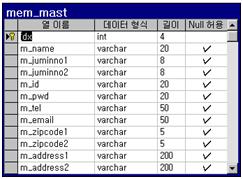
인덱스는 자동증가 값인 IDX 컬럼에만 잡혀있다. 필자가 보기에는 자동 증가값이 과연 ‘회원’ 이라는 테이블에 쓸모가 있을까? 하는 생각이 든다. 회원 수 나타내려고? 이것은 ‘회원’이라는 것을 완전히 무시한 처사라고 생각한다. 필자가 ‘YASICOM’ 이라는 아이디와 ‘1111’ 이라는 패스워드를 가지고 회원가입을 했다. 그러나 각각의 회원을 구별할 수 있고, 그 회원을 대표할 수 있는 것이 고작 1, 2, 3 과 같은 아무 의미 없는 숫자라는 것은 너무하다 싶다. IDX 컬럼을 빼곤 모두 널값을 허용하고 있다. 그러면 모두 어플리케이션에서 처리해볼 작정인 것이다. 별로 좋지 않다. 누누히 얘기하지만 데이터베이스는 현실을 반영하는 것이다. 현실을 반영한 것이 가입한 회원의 아이디가 ‘알지 못하는 값’ 이 되어서야 되겠는가? 또한 위에서 보이는 M_JUMINNO1, M_JUMINNO2 와 같이 컬럼이 왜 나누어 져야 하는지를 필자는 잘 모르겠다. 물론 어플리케이션에서의 편의성도 있긴 하지만 필자가 알기로는 주민등록번호를 체크하는 알고리즘은 가중치 코드이다. 주민등록 번호에 대한 알고리즘은 다음과 같다.
ABCDEF-ABCDEFG <- 주민등록번호
G : KEY POINT NUMBER
SUM = 2A + 3B + 4C + 5D + 6E + 7F + 8A + 9B + 2C + 3D + 4E + 5F
TEMP = 11 - MOD(SUM,11)
THEN,
G = TEMP1
만약 주민등록번호 체크를 위해서면 한 개의 컬럼으로 합치는 것이 더 좋을 것이다. 어떤 개발자는 하이픈(-) 이 섞이면 어떻게 하는가에 대한 걱정을 한다. 그리고 주민등록번호 컬럼을 13자리로 할 것인가 하이픈을 포함해서 14자리로 할 것인가에 대한 고민을 하고는 한다. 그러나 이런 걱정을 할 필요가 없다. 이유는 다음을 보면 알 수 있을 것이다.
USE TEMPDB
GO
CREATE TABLE TEST_JUMIN(
JUMIN_NO VARCHAR(14)
)
GO
INSERT TEST_JUMIN VALUES('761118-1400418')
INSERT TEST_JUMIN VALUES('7611181400418')
GO
SELECT REPLACE(JUMIN_NO, '-', '') FROM TEST_JUMIN
------------
7611181400418
7611181400418
(2개 행 적용됨)
만약에 하이픈에 대한 검사를 하고 싶다면 다음과 같은 함수를 사용하면 된다.
SELECT PATINDEX('%-%', JUMIN_NO) FROM TEST_JUMIN
-----------
7
0
(2개 행 적용됨)
또 한가지 상당히 눈에 거슬리는 부분이 있다. 저장 프로시저의 쿼리문을 보자. WHERE절에 명시된 조건이 ‘WHERE M_ID=@M_ID’ 임에도 불구하고, 회원들이 로그인을 수시로 할 것임에도 불구하고, 인덱스는 기본키에만 잡혀있다. 그것도 테이블에 하나밖에 쓸 수 없는 중요한 클러스터드 인덱스를 말이다.
이제 보안에 대한 것을 살펴보자. 위에서도 언급했듯이 저장 프로시저로 캡슐화한 부분은 높이 살만하다. 그러나 아이디와 패스워드의 경우는 상당히 중요한 데이터이다. 이러한 부분에서 “존재하지 않는 아이디입니다.” 또는 “패스워드가 틀렸습니다.”라는 식의 사용자 메시지는 명시적으로 아이디 또는 패스워드의 정확성을 알려주는 셈이 된다. 보안상으로는 “아이디와 패스워드가 틀렸습니다.” 내지는 “아이디와 패스워드가 일치하지 않습니다.”의 식이 되어야 한다고 생각한다. 만약 나쁜 마음을 먹고 있는 사람에게 경우의 수를 1/2로 줄여준다는 것은 좋은 경우라는 생각이 들지 않는다. 그러나 사용자에게 잘못된 입력을 하였다는 메시지는 필요할 수도 있다. 이와 같은 것은 사용자와의 협상의 대상이 된다. 만약 필자의 경우라면 M_ID + M_PSW 형태의 결합 인덱스를 프라이머리키로 잡고, 클러스터드 인덱스를 생성하여 다음과 같이 저장 프로시저를 만들 것이다. 아래의 경우는 논클러스터드 인덱스로 결합인덱스만을 만든 예이다.
CREATE UNIQUE INDEX IDX_ID_PWD
ON MEM_MAST(M_ID, M_PWD)
GO
CREATE PROCEDURE USP_MEM_LOGIN
@M_ID VARCHAR(20),
@M_PWD VARCHAR(20)
AS
BEGIN
SET LOCK_TIMEOUT 30000
SET NOCOUNT ON
IF EXISTS(SELECT M_ID, M_PWD FROM MEM_MAST
WHERE M_ID = @M_ID AND M_PWD = @M_PWD)
RETURN 1
ELSE
RETURN 0
SET NOCOUNT OFF
SET LOCK_TIMEOUT 1
END
GO
DECLARE @RETURN INT
EXEC @RETURN = DBO.USP_MEM_LOGIN @M_ID = 'TEST', @M_PWD = 'TEST'
SELECT @RETURN
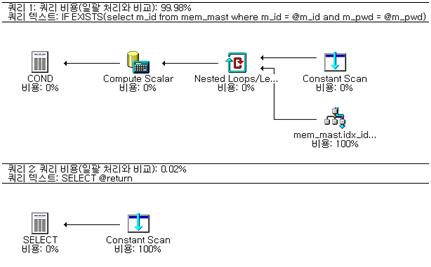
다음은 실행계획이다.
살펴보자면 먼저 SET LOCK_TIMEOUT 30000, SET NOCOUNT ON 이 걸린다. 이것은 LOCK이 걸렸을 경우 잠금 제한 시간을 30초로 한다는 것이다. 블록킹이나 데드락은 실제로 그렇게 많은 부하를 주는 것은 아니나 Queue에 작업이 쌓이게 되어 갑자기 서버의 자원을 많이 사용하게 하는데 있다. 또한 카운트를 세지 않으므로 해서 클라이언트가 요청한 데이터를 제공해 줄 때 부가적인 데이터를 전송하지 않음으로써 네트웍 트래픽을 줄이는데 한 역할을 하게한다. 또한 저장 프로시저를 사용함에 있어서 소유자에 대한 명시를 하였다. 소유자에 대한 명시도 역시 권장 사항이다. 왜냐하면 컴파일 락을 걸 필요가 없기 때문에 경합을 감소시켜주고, 블록킹의 발생 가능성을 줄여주기 때문이다. 위와 같은 저장프로시저는 7.0 버전부터 있었던 자동매개변수화 되어서 실행계획이 캐싱된다. 다음과 같이 저장 프로시저를 고칠 수도 있다. 이렇게 하면 바로 결과를 리턴 받을 수 있다. 또한 OPTION(KEEPFIXED PLAN) 를 사용함으로써 재컴파일 되지 않게 한다. (사실 이 저장 프로시저에서는 OPTION(KEEPFIXED PLAN)의 사용은 쓸모가 있지는 않다.)
ALTER PROCEDURE USP_MEM_LOGIN @M_ID VARCHAR(20) = NULL, @M_PWD VARCHAR(20) = NULL AS BEGIN SET LOCK_TIMEOUT 30000 SET NOCOUNT ON IF(@M_ID IS NULL AND @M_PWD IS NULL) GOTO HELP IF EXISTS(SELECT M_ID, M_PWD FROM MEM_MAST WHERE M_ID = @M_ID AND M_PWD = @M_PWD) SELECT '로그인 성공' OPTION(KEEPFIXED PLAN) ELSE SELECT '로그인 실패' OPTION(KEEPFIXED PLAN) HELP: BEGIN SELECT '사용법: EXEC USP_MEM_LOGIN ' + '사용자ID ,' + '패스워드' OPTION(KEEPFIXED PLAN) --RETURN -1 END END GO
이제 실행 계획을 살펴보자. 먼저 IDX_ID_PWD 인덱스를 사용하여 INDEX SEEK한 것이 보인다. 이것은 인덱스 검색을 한 것이다. 바로 인덱스를 이용해서 한 개의 행을 검색한 것이다.
CONSTANT SCAN은 EXISTS 연산자의 사용 때문에 보여진 것이다. CONSTANT SCAN은 행을 스캔하기는 하지만 데이터는 포함되지 않은 상태로 데이터를 반환한다. 그러므로 이 연산자는 데이터 행의 존재 유무 판단이 중요할 때 사용된다.
NESTED LOOPS/LEFE SEMI JOIN의 경우는 물리/논리 연산자이다. 이것은 IF EXISTS(..)의 연산과정을 나타낸다. COMPUTE SCALAR의 경우는 EXISTS의 연산을 말하는 것이다. 즉, 식이 값을 계산하여 스칼라값을 만드는 것이다. TRUE, FALSE의 값이다. COND는 마우스를 가져다 대면 알겠지만 IF EXISTS(SELECT ..) 연산의 결과이다. 예상 결과집합은 1개이다. 마지막으로 SELECT 1 또는 SELECT 0 을 수행한다.
중요한 것은 INDEX SEEK에서 대부분의 비용을 소모했다는 것이다. 쿼리를 보면 알겠지만 여기서는 커버드 쿼리가 실행된다. 커버드 쿼리는 SELECT리스트에 컬럼이 나타날때 이 컬럼이 모두 넌클러스터드 인덱스의 결합인덱스로 생성되어 있을 경우 오로지 넌클러스터드 인덱스만을 찾아서 데이터를 보여주면 되므로 성능 향상을 기대할 수 있다. 여기서는 인덱스의 사용 올바른 것이지만 판단하면 될 것이다.
항상 실행계획을 볼 때는 가장 많은 비용이 차지하는 부분을 보면 된다. 여기서는 쿼리1에서 99.98%의 비용이 소모되었고, 그 중에 INDEX SEEK에서 100%가 소모되었다. 그러므로 이러한 부분을 집중적으로 살펴본다면 성능을 향상시키는데 상당한 도움을 될 것이다. 또한 저장 프로시저의 사용법을 GOTO 레이블을 이용하여 @M_ID, @M_PWD에 아무것도 넣지 않는다면 HELP레이블로 이동하여 사용법을 보여주는 로직을 구현했다. 만약 @M_ID, @M_PWD에 어떤 계산을 수행한다면 주의하여야 할 것이다. 왜냐하면 이 값들은 NULL값으로 초기화 되어 있기 때문이다.
마지막으로 살펴볼 것은 인덱스 생성시에 WITH <INDEX_OPTION> 에 있는 FIILFACTOR 옵션이다. 이 옵션은 인덱스 생성시의 페이지에 대한 채우기 비율이다. 만약 이 옵션에 FILLFACTOR = 100 이라고 선언한다면 MSSQL SERVER는 인덱스를 페이지에 꽉 채우게 된다. 90으로 한다면 90%는 채우고 10%는 삽입, 갱신을 위해서 남겨논다는 뜻이 된다.
이제 FILLFACTOR가 뭔지 알았으니 로그인에 대한 것에서 FILLFACTOR옵션이 작용하는 영향에 대해서 살펴보자. 사용자에게 서비스를 개시한 초기의 시스템의 경우를 생각해보자. OLTP환경이라면 상당히 많은 수의 사용자가 로그인을 시도할 것이고, OLAP환경이라면 그다지 많은 수의 사용자는 아닐 것이다. OLAP환경에서는 사용자의 추가가 일어날 일이 별로 없을 것이므로 FILLFACTOR의 값을 100으로 해도 그다지 영향이 없을 것이다. 그러나 OLTP환경 특히, 웹환경이라면 시스템이 사용자에게 서비스를 개시하고 얼마 동안은 많은 수의 입력, 수정이 일어날 것이다. 그러므로 FILLFACTOR의 값을 적당한 선에서 낮게 설정하는 것이 성능에 도움을 줄 것이다. 그렇다고 FILLFACTOR에 100% 의존할 수 없으므로 관리자는 주기적으로 인덱스를 REBUILD해줘야 할 것이다. INDEX REBUILD할 때는 WITH DROP_EXISTING를 이용해서 재생성하던지 아니면 DROP INDEX후 다시 CREATE INDEX를 하면 되겠다. 시스템이 사용자에게 제공하는 서비스의 특성에도 FILLFACTOR는 영향을 받아야 한다. 위에서 이야기 했듯이 서비스의 초기에는 많은 양의 삽입, 갱신이 이루어 질 것이나 어느 정도 기간이 지난다면 삽입, 갱신의 양은 줄어들 것이므로 상황에 따라서 FILLFACTOR의 값을 조정하여 인덱스를 재생성해 주면 되겠다.
FILLFACTOR의 값을 60이하로 잡는 것은 상당히 많은 고려를 해야 할 것이다. 왜냐하면 FILLFACTOR가 100보다 작으면 작을수록 검색의 성능은 떨어지기 때문이다. 이유는 삽입, 수정을 위해 남겨놓는 공간으로 인해서 인덱스를 이용할 때 더 많은 페이지를 읽어야 하기 때문이다. 또한 FILE_GROUP을 이용해서 적절히 인덱스와 로그, 실제 데이터, 시스템 데이터에 대한 디스크 분산이 이루어지게 해야 할 것이다. 이러한 분산에 대한 것은 분산에 대한 솔루션을 참고하기 바란다.
아이디와 패스워드를 결합인덱스로 묶고, PK로 결정한다는 것은 해당 조직의 정책과 관련이 이 있다. 왜냐하면 중복된 아이디가 나올 수 있기 때문이다. 중복된 아이디를 허용한다고 하더라도 만일 패스워드와 아이디가 일치하는 것이 존재한다면 아이디와 패스워드의 유출 위험성이 아주 작게라도 발생하기 때문이다. 이러한 부분은 해당 조직과 협의하여야 할 문제이다. 물론 패스워드는 대소문자를 구분하는 것도 문제가 될 수 있다. 대소문자 구분과 저장 프로시저의 IF 부분에 대한 처리는 다음과 같이 해결될 수 있는 문제이다.
CREATE TABLE #MEMBER(ID VARCHAR(12),
PW VARCHAR(12) COLLATE SQL_LATIN1_GENERAL_CP437_CS_AS) )
INSERT INTO #MEMBER VALUES ('YASI', '1111')
GO
--1: 로그인 성공 0:로그인 실패
SELECT CASE WHEN (SELECT 1 FROM #MEMBER WHERE ID = 'YASI' AND PW = '1111') = 1
THEN 1 ELSE 0 END
FROM (SELECT 1 A) T
-----------
1
--또는
SELECT CASE WHEN (SELECT 1 FROM #MEMBER WHERE ID = 'YASI' AND PW = '1111') = 1
THEN '로그인성공' ELSE '로그인실패' END
FROM (SELECT 1 A) T
----------
로그인성공
이렇게 직접적인 처리가 가능하다. 이러한 개발 방법은 코딩량과 처리량을 줄여줄 것이다. 한가지 문제는 패스워드의 대소문자에 대한 부분이다. 대소문자는 컬럼에서 COLLATE를 지정하면 해당 컬럼은 대소문자 구별을 해서 해결된다. 물론 위에서 해당 프로시저의 IF부분을 없애고 다음과 같이 작성해도 된다.
CREATE TABLE #TEMP(
CH VARCHAR(10) COLLATE SQL_LATIN1_GENERAL_CP437_CS_AS)
INSERT INTO #TEMP VALUES('PASSWORD')
GO
--결과는 0
SELECT CASE WHEN (SELECT CH FROM #TEMP) = 'password' THEN 1 ELSE 0 END
FROM (SELECT 1 ID) T
--결과는 1
SELECT CASE WHEN (SELECT CH FROM #TEMP) = 'PASSWORD' THEN 1 ELSE 0 END
FROM (SELECT 1 ID) T
GO
M_ID + M_PSW로 PK를 잡는다면 ID가 중복되는 것이 나타날 수도 있다. 이럴 때 어플리케이션의 로직이 필요한 것이다. 이러한 것은 ID가입을 받기 전 ID 중복체크를 하면 되는 것이다.
[edit]
3 데이터베이스는 현실을 반영한다 #
실제로 데이터베이스 설계에 관련된 것은 개발방법론과 모델링과 관련이 많이 있다. 개념설계에서는 정규화라는 도구가 검증의 도구이며, 성능 향상의 도구이다. 데이터의 중복을 없애고, 여러 이상현상들을 없앰으로써 무결성과 성능을 보장하는 최고의 도구이다. 제품 출시 이후 설계 튜닝을 하는 경우는 매우 드물며, 대부분은 어플리케이션 튜닝 후 하드웨어의 증설로 이어지는 프로세스를 밟는다.
가끔 모델링과 설계의 차이점을 묻고는 한다. 필자는 모델링은 설계의 과정으로 보고 있다. 그 중 모델링은 정보시스템의 성능을 결정짓는 가장 중요한 과정으로 보고 있으며, 대부분의 성능에 대한 사항들은 여기서 결정된다. 또한 이러한 과정은 개발시간의 단축으로도 이어진다. 그러므로 모델링과 설계 단계의 튜닝은 아무리 강조해도 지나침이 없다. 대부분의 모델링과 설계의 튜닝은 데이터베이스의 기초 개념으로부터 출발한다. 그러므로 정규화뿐만 아니라 모델링의 전 과정을 하나하나 명확히 집고 넘어가야 할 필요성을 가진다. 이제 개발방법론과 개념 그리고 모델링의 방법에 대한 포인트를 언급해 나갈 것이다. 거듭 말하지만 모델링과 설계는 정보시스템 개발 과정중 가장 중요한 튜닝 단계이다. 각각의 단계에서 명확히 집고 넘어가지 않는다면 어플리케이션의 부담으로 넘어가게 되므로 오버헤드를 가중시킨다. 데이터 모델링은 복잡한 현실을 단순화(추상화)하여 표현한 것이다. 그러므로 모델은 반드시 현실을 반영해야 한다. 물론 물리적으로 구현된 시스템도 현실을 반영해야 한다. 다음을 보자.
| 사원 개체집합과 부서 개체집합이 있다. 물론 부서:사원 = 1:다 의 관계이다. 관계명은 "소속" 쯤으로 해두자. 물리적으로 변환(관계형)하면 사원테이블쪽에 부서번호라는 컬럼이 있고 이것은 부서테이블에서 온 외부키이다. 그 외부키에는 NULL값이 허용되었다. 이 NULL 허용이 뜻하는 바가 무엇이겠는가? |
위의 질문에 답을 하지 못했다면 설계의 시도조차 하지 말아야 한다. 왜냐하면 데이터베이스가 현실을 반영했는지조차 모르는 상태이기 때문이다. 현실과의 일치성 결여는 시스템에 대한 사용자의 외면으로 이어지고 실패한 프로젝트가 되기 때문이다. 위 문제의 답을 하자면 사원은 자신이 소속될 부서가 없이도(소속될 부서가 결정되지 않았더라도) 즉, 소속부서가 없이도 존재가 가능하다라고 답 할 수 있다. 즉, 사용자의 회사 사원들 중에서 어떤 부서에도 소속되지 않은 사원이 있냐? 고 물었을 때 동의 한다면 물리적으로는 위처럼 된다. 물론 여기서 끝나면 80점이다. 사원이 기본적으로 소속될 부서를 만들어주어 정보의 단절을 막는 것도 설계자의 몫이다. 예를 들면 소속부서가 없는 사원은 기본적으로 총무부에 속하게 하면 되는 것이거나 가상의 부서를 만들어도 된다. 이렇게 현실을 반영하고 다듬어 다음과 같은 ERD를 그렸다고 해보자.

그리고 테이블을 만들었다고 가정하자. insert into 사원 value (...) 과 같이 사원테이블에 한 행을 삽입한다고 해보자. 분명히 RDBMS는 오류를 리턴 할 것이다. 오라클에서 보면 다음과 같이 ORA-02291에러를 리턴할 것이다.
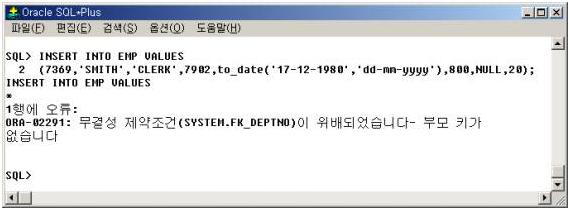
단순히 무결성 제약조건 위배인가? 여기에서 끝난다면 안 된다. 이 무결성 제약조건이라는 용어가 현실세계에서 의미하는 바를 정확히 알아야 한다는 뜻이다. 즉, 사원이 소속될 부서가 없기 때문에 일어난 오류임을 알아야 한다. 위 ERD는 사원은 반드시 자기가 소속될 부서를 배정받아야만 그 회사의 사원이 될 수 있으며, 부서의 경우는 그 부서에서 일하는 사람이 없는 부서가 존재할 수도 있는 것이다. 데이터베이스는 현실을 반영한다. 우리가 말하는 “전산화”라는 것은 현실세계의 일을 컴퓨터세계로 옮기는 작업일 뿐이다. 그러므로 현실세계와 컴퓨터세계와는 반드시 “일치성”을 가지는 것이 지극히 정상적임을 알아야 한다.