[edit]
2 예제 #
#two_moon 데이터 셋
from sklearn.datasets import make_moons
import pandas as pd
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
df = pd.DataFrame(X, columns=["x", "y"])
df["group"] = y
df[:5]
#import matplotlib.pyplot as plt
#plt.scatter(x=df.x, y=df.y, c=df.group)
#<scatter plot>: 여기부터
import matplotlib.pyplot as plt
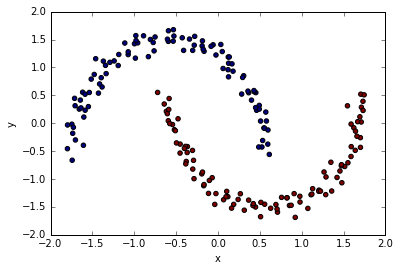
plt.scatter(x=df.x, y=df.y, c=df.group)
fig, ax = plt.subplots()
colors = {1:'red', 0:'blue'}
grouped = df.groupby('group')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
plt.show()
#</scatter plot>: 여기까지 한번에 실행
#표준화(평균=0, 분산=1)
from sklearn.preprocessing import StandardScaler
scale = StandardScaler()
scale.fit(df[["x", "y"]])
scaled_X = scale.transform(df[["x", "y"]])
df["scaled_x"] = scaled_X[:,0]
df["scaled_y"] = scaled_X[:,1]
#DBSCAN
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=5) #기본값이다.
cluster = dbscan.fit_predict(scaled_X)
df["cluster"] = cluster
#clustering 결과 확인
plt.scatter(x=df.scaled_x, y=df.scaled_y, c=df.cluster)
plt.xlabel("x")
plt.ylabel("y")
결과