sql server 2016 sp1(cu3) мқҙнӣ„ лІ„м „мқҖ ENABLE_PARALLEL_PLAN_PREFERENCE нһҢнҠёлҘј м“°л©ҙ лҗңлӢӨ.
https://www.mssqltips.com/sqlservertip/4939/how-to-force-a-parallel-execution-plan-in-sql-server-2016/
https://www.mssqltips.com/sqlservertip/4939/how-to-force-a-parallel-execution-plan-in-sql-server-2016/
мқҙ л¬ём„ңмқҳ лӮҙмҡ©мқҖ SQL Server Magazine 2010л…„ 7мӣ”нҳём—җ к°ңмһ¬лҗң лӮҙмҡ© л°Ҹ н•„мһҗк°Җ н’Җм–ҙ м“ҙ кІғмқҙлӢӨ. к°Ғк°Ғмқҳ 2005(sp3), 2008(sp1) лІ„м „мқҳ SQL Serverк°Җ м„Өм№ҳлҗң н…ҢмҠӨнҠё нҷҳкІҪмқҙ н•„мҡ”н•ҳлӢӨ. (мқҙ л¬ём„ңлҠ” 2008R2м—җм„ң н…ҢмҠӨнҠён•Ё.) лӢӨмқҢмқҳ мҪ”л“ңлҘј 2005, 2008 к°Ғ лІ„м „мқҳ мқёмҠӨн„ҙмҠӨм—җм„ң мӢӨн–үмӢңнӮЁлӢӨ.
[edit]
1 мҝјлҰ¬н”Ңлһң비көҗ1:Join #
н…ҢмҠӨнҠё мӨҖ비
-- Sample datatabase
SET NOCOUNT ON;
IF DB_ID('testparallel') IS NULL CREATE DATABASE testparallel;
GO
USE testparallel;
GO
-- Helper function GetNums
-- returns a sequence of integers of a requested size
IF OBJECT_ID('dbo.GetNums', 'IF') IS NOT NULL
DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@n AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS(SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT TOP (@n) n FROM Nums ORDER BY n;
GO
USE testparallel;
IF OBJECT_ID('dbo.T1') IS NOT NULL DROP TABLE dbo.T1;
IF OBJECT_ID('dbo.T2') IS NOT NULL DROP TABLE dbo.T2;
GO
CREATE TABLE dbo.T1
(
col1 INT NOT NULL,
col2 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT(0x)
);
CREATE UNIQUE CLUSTERED INDEX idx_cl_col1 ON dbo.T1(col1);
INSERT INTO dbo.T1 WITH(TABLOCK) (col1, col2)
SELECT n AS col1, n AS col2
FROM dbo.GetNums(1000000);
SELECT * INTO dbo.T2 FROM dbo.T1;
CREATE UNIQUE CLUSTERED INDEX idx_cl_col1 ON dbo.T2(col1);
GO
лӢӨмқҢмқҳ SQLмқ„ 2005, 2008 к°Ғ мқёмҠӨн„ҙмҠӨм—җм„ң мӢӨн–үмӢңмјңліҙмһҗ.
SELECT * FROM dbo.T1 JOIN T2 ON T1.col1 = T2.col1 WHERE T1.col2 <= 100;
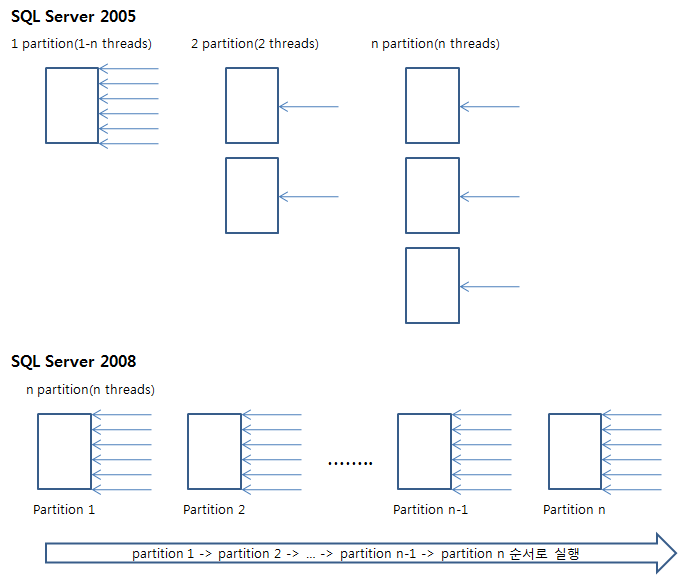
2005 лІ„м „
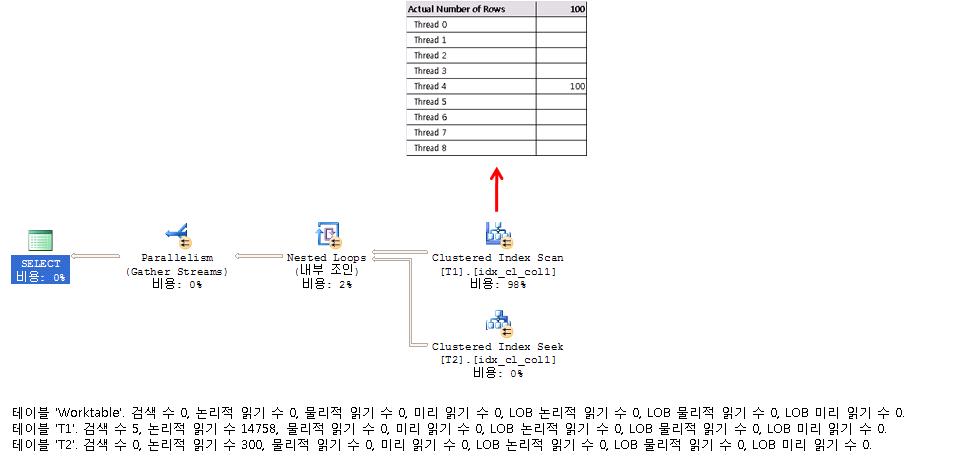
2008 лІ„м „
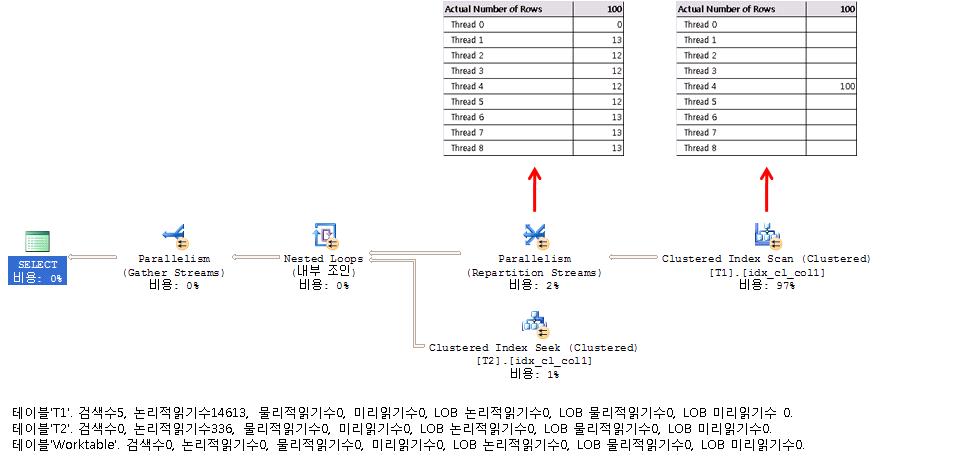
2005лІ„м „мқҳ кІҪмҡ°лҠ” Thread 4лҘј м ңмҷён•ҳкі лҠ” мһ‘м—…мқ„ н•ҳм§Җ м•Ҡмқ„ н…Ңм§Җл§Ң, 2008мқҳ кІҪмҡ°лҠ” мІ« лІҲм§ё мһ‘м—…мқ„ лҒқлӮҙкі лӮң кІ°кіјлҘј лӢӨмӢң м—¬лҹ¬ Threadм—җ 분배함мңјлЎңмҚЁ лӢӨмқҢ мһ‘м—…мқ„ мҲҳмӣ”н•ҳкІҢ н•ҙмӨҖлӢӨ.
[edit]
2 мҝјлҰ¬н”Ңлһң비көҗ2:Star Join #
н…ҢмҠӨнҠё мӨҖ비
USE testparallel;
IF OBJECT_ID('dbo.Fact', 'U') IS NOT NULL DROP TABLE dbo.Fact;
IF OBJECT_ID('dbo.Dim1', 'U') IS NOT NULL DROP TABLE dbo.Dim1;
IF OBJECT_ID('dbo.Dim2', 'U') IS NOT NULL DROP TABLE dbo.Dim2;
IF OBJECT_ID('dbo.Dim3', 'U') IS NOT NULL DROP TABLE dbo.Dim3;
GO
CREATE TABLE dbo.Dim1
(
key1 INT NOT NULL CONSTRAINT PK_Dim1 PRIMARY KEY,
attr1 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT (0x)
);
CREATE TABLE dbo.Dim2
(
key2 INT NOT NULL CONSTRAINT PK_Dim2 PRIMARY KEY,
attr1 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT (0x)
);
CREATE TABLE dbo.Dim3
(
key3 INT NOT NULL CONSTRAINT PK_Dim3 PRIMARY KEY,
attr1 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT (0x)
);
CREATE TABLE dbo.Fact
(
key1 INT NOT NULL CONSTRAINT FK_Fact_Dim1 FOREIGN KEY
REFERENCES dbo.Dim1,key2 INT NOT NULL CONSTRAINT FK_Fact_Dim2 FOREIGN KEY
REFERENCES dbo.Dim2,
key3 INT NOT NULL CONSTRAINT FK_Fact_Dim3 FOREIGN KEY REFERENCES dbo.Dim3,
measure1 INT NOT NULL,
measure2 INT NOT NULL,
measure3 INT NOT NULL,
filler BINARY(100) NOT NULL DEFAULT (0x),
CONSTRAINT PK_Fact PRIMARY KEY(key1, key2, key3)
);
INSERT INTO dbo.Dim1(key1, attr1)
SELECT n, ABS(CHECKSUM(NEWID())) % 20 + 1
FROM dbo.GetNums(100);
INSERT INTO dbo.Dim2(key2, attr1)
SELECT n, ABS(CHECKSUM(NEWID())) % 10 + 1
FROM dbo.GetNums(50);
INSERT INTO dbo.Dim3(key3, attr1)
SELECT n, ABS(CHECKSUM(NEWID())) % 40 + 1
FROM dbo.GetNums(200);
INSERT INTO dbo.Fact WITH (TABLOCK)
(key1, key2, key3, measure1, measure2, measure3)
SELECT N1.n, N2.n, N3.n,
ABS(CHECKSUM(NEWID())) % 1000000 + 1,
ABS(CHECKSUM(NEWID())) % 1000000 + 1,
ABS(CHECKSUM(NEWID())) % 1000000 + 1
FROM dbo.GetNums(100) AS N1
CROSS JOIN dbo.GetNums(50) AS N2
CROSS JOIN dbo.GetNums(200) AS N3;
GO
лӢӨмқҢмқҳ SQLмқ„ 2005, 2008 к°Ғ мқёмҠӨн„ҙмҠӨм—җм„ң мӢӨн–үмӢңмјңліҙмһҗ. (Star Join м°ёкі )
SELECT * FROM dbo.Fact AS F JOIN dbo.Dim2 AS D2 ON F.key2 = D2.key2 JOIN dbo.Dim3 AS D3 ON F.key3 = D3.key3 WHERE D2.attr1 <= 3 AND D3.attr1 <= 2;
2005 лІ„м „
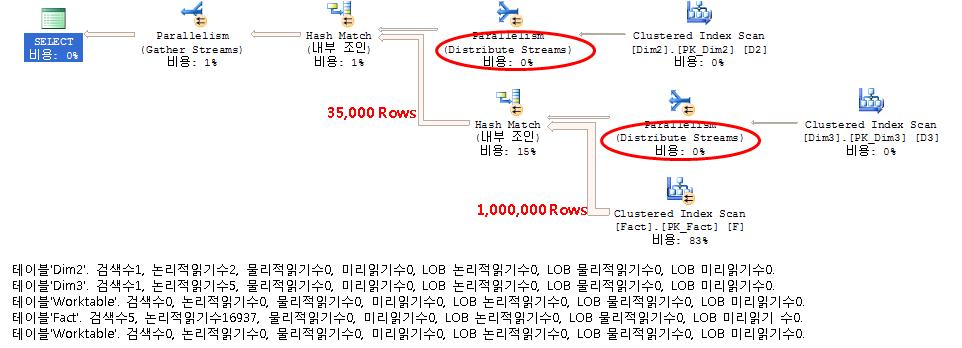
2008 лІ„м „
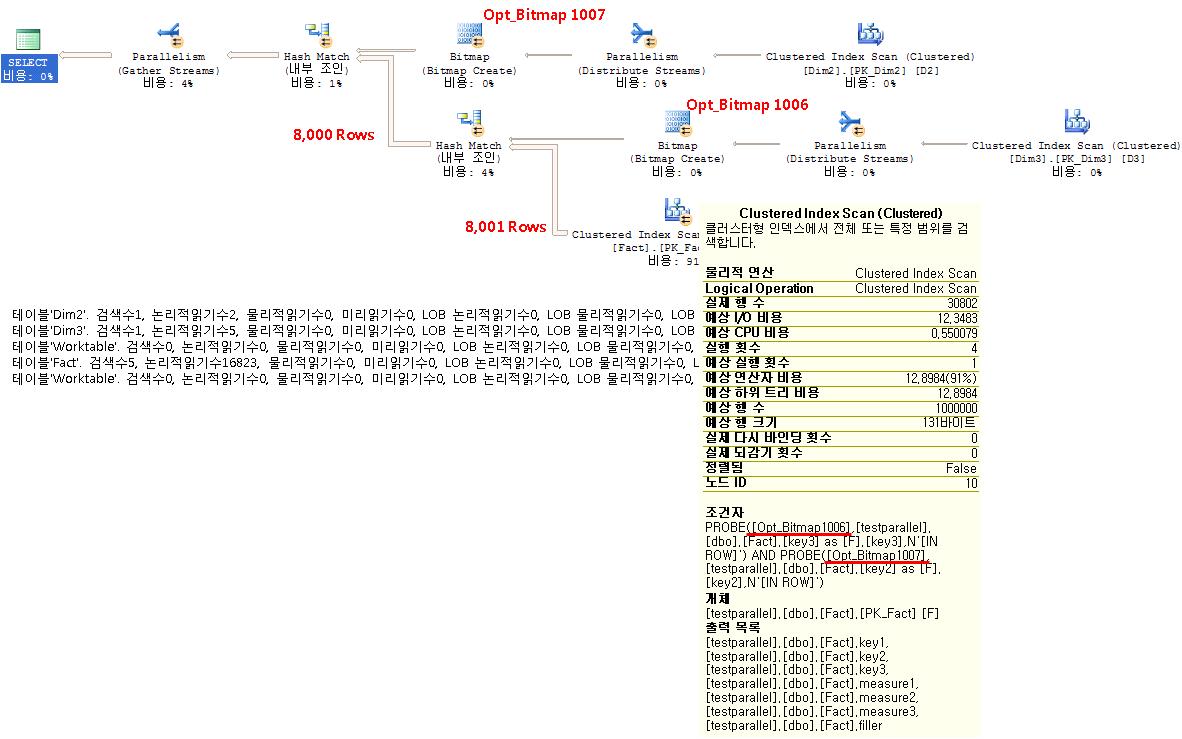
мЎ°мқё нҡҹмҲҳлҘј нҷ• мӨ„м—¬мЈјлҠ” кІғмқҙ нҸ¬мқёнҠёлӢӨ.
[edit]
3 мҝјлҰ¬н”Ңлһң비көҗ3:Partitioning #
кё°ліё
н…ҢмҠӨнҠё мӨҖ비
USE testparallel;
IF OBJECT_ID('dbo.PartitionedTable', 'U') IS NOT NULL
DROP TABLE dbo.PartitionedTable;
IF EXISTS(SELECT * FROM sys.partition_schemes WHERE name = 'PS1')
DROP PARTITION SCHEME PS1;
IF EXISTS(SELECT * FROM sys.partition_functions WHERE name = 'PF1')
DROP PARTITION FUNCTION PF1;
GO
CREATE PARTITION FUNCTION PF1 (INT)
AS RANGE LEFT FOR VALUES (250000, 500000, 750000);
CREATE PARTITION SCHEME PS1
AS PARTITION PF1 ALL TO ([PRIMARY]);
CREATE TABLE dbo.PartitionedTable
(
col1 INT NOT NULL,
col2 INT NOT NULL,
filler BINARY(100) DEFAULT(0x)
) ON PS1(col1);
CREATE UNIQUE CLUSTERED INDEX idx_col1 ON dbo.PartitionedTable(col1) ON PS1(col1);
INSERT INTO dbo.PartitionedTable WITH (TABLOCK) (col1, col2)
SELECT n, ABS(CHECKSUM(NEWID())) % 1000000 + 1
FROM dbo.GetNums(1000000);
лӢӨмқҢмқҳ SQLл¬ёмқ„ 2005, 2008мқҳ к°Ғк°Ғмқҳ мқёмҠӨн„ҙмҠӨм—җм„ң мӢӨн–үмӢңмјңліёлӢӨ.
SELECT * FROM dbo.PartitionedTable WHERE col1 <= 500000 ORDER BY col2;
2005 лІ„м „
2008 лІ„м „
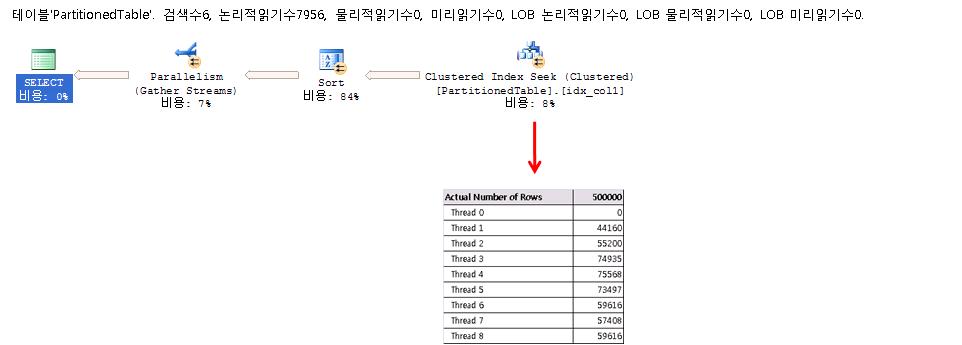
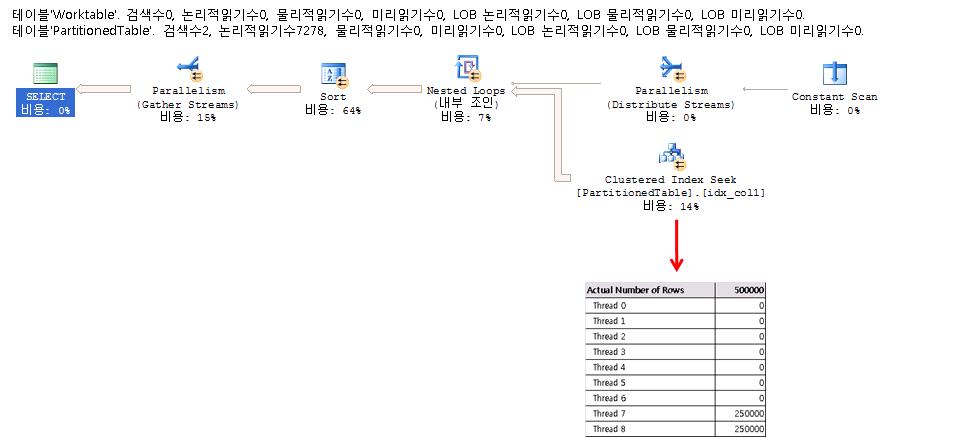
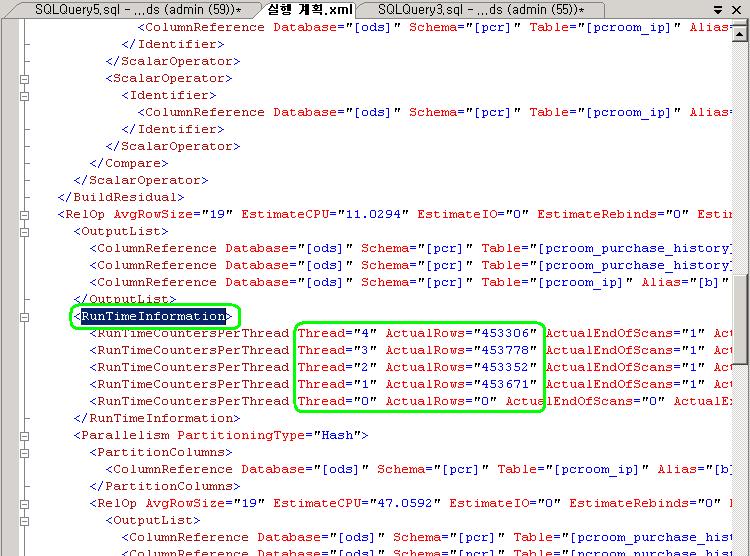
мӢӨм ңмӢӨн–үкі„нҡҚмқ„ xmlлЎң л– м„ң ліҙл©ҙ лӘҮк°ңмқҳ threadк°Җ мӮ¬мҡ©лҗҳм—Ҳмңјл©°, к°Ғк°Ғмқҳ threadк°Җ лӘҮк°ңмқҳ rowлҘј мІҳлҰ¬н–ҲлҠ”м§Җ ліј мҲҳ мһҲлӢӨ. Ctrl+Lмқ„ лҲҢлҹ¬м„ң лӮҳмҳӨлҠ” мҳҲмғҒмӢӨн–үкі„нҡҚм—җм„ңлҠ” ліј мҲҳ м—ҶлӢӨ. м•„лһҳмқҳ к·ёлҰјмІҳлҹј <RunTimeInformation> ... </RunTimeInformation> нғңк·ёл¶Җ분мқ„ ліҙл©ҙ лҗңлӢӨ. н‘ңмӢңлҗң л¶Җ분мқ„ ліҙл©ҙ мҙқ 5к°ңмқҳ threadк°Җ мӮ¬мҡ©лҗҳм—Ҳмңјл©°, к°Ғк°Ғмқҳ threadлҠ” лҢҖлһө 4л§Ң5мІң rowм”©мқ„ мІҳлҰ¬н•ң кІғмқ„ ліј мҲҳ мһҲлӢӨ.
[edit]
4 лі‘л ¬мІҳлҰ¬ к°•м ңнҷ” #
мқҙ л°©лІ•мқҖ л¬ём„ңнҷ”лҗҳм§Җ м•ҠмқҖ dbcc лӘ…л №мқ„ нҶөн•ҙ кө¬нҳ„н• мҲҳ мһҲлӢӨ. cpuмҷҖ ioм—җ лҢҖн•ң к°ҖмӨ‘м№ҳлҘј мҳөнӢ°л§Ҳмқҙм Җм—җкІҢ м•Ңл ӨмӨ„ мҲҳ мһҲлӢӨ. мөңмў…м Ғмқё мҝјлҰ¬ 비мҡ©мқҙ м„Өм •лҗң к°’(кё°ліёк°’ = 5)ліҙлӢӨ нҒ¬л©ҙ лі‘л ¬мІҳлҰ¬н•ҳлҜҖлЎң cpuм—җ лҢҖн•ң к°ҖмӨ‘м№ҳлЎң лі‘л ¬мІҳлҰ¬лҘј мң лҸ„н• мҲҳ мһҲлӢӨ. лЁјм Җ м„Өм •к°’мқ„ ліёлӢӨ.
DBCC TRACEON (3604); -- Show DBCC output DBCC SHOWWEIGHTS; -- Show the settings /* кІ°кіј DBCC Opt Weights CPU: 1.000000 IO: 1.000000 SPID 81 */
лі‘л ¬мІҳлҰ¬ н•ҳм§Җ м•ҠлҠ” мҝјлҰ¬мқҳ мӢӨн–ү кі„нҡҚмқ„ ліҙмһҗ.
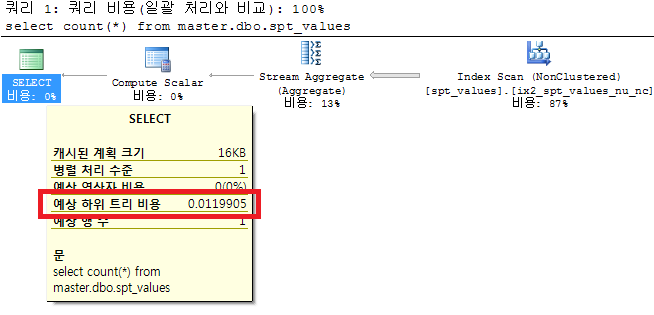
select count(*) from master.dbo.spt_values
мң„ к·ёлҰјмқ„ ліҙл©ҙ м•Ң мҲҳ мһҲкІ м§Җл§Ң лі‘л ¬мІҳлҰ¬ н•ҳм§Җ м•ҠлҠ”лӢӨ. cpuм—җ к°ҖмӨ‘м№ҳлҘј мЈјм–ҙ мҝјлҰ¬ 비мҡ©мқ„ 5к°Җ л„ҳм–ҙк°ҖлҸ„лЎқ мЎ°м •н•ҙ ліҙмһҗ.
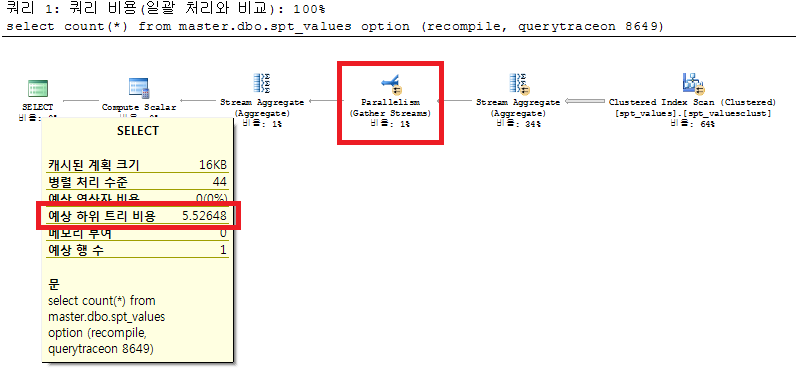
DBCC FREEPROCCACHE DBCC SETCPUWEIGHT(10000); go select count(*) from master.dbo.spt_values option (recompile, querytraceon 8649) -- мҳөм…ҳмқҖ кјӯ н•„мҡ”н•ҳлӢӨ. go DBCC SETCPUWEIGHT(1); -- мӣҗлһҳлҢҖлЎң н•ҙлҶ“мһҗ. DBCC SETIOWEIGHT(1); --ioм—җлҸ„ к°ҖмӨ‘м№ҳлҘј мӨ„ мҲҳ мһҲлӢӨ. go
н•„мһҗмқҳ кІҪмҡ°лҠ” cpuм—җ 10000 м •лҸ„лҘј мЈјм—ҲлҚ”лӢҲ мҝјлҰ¬ 비мҡ©мқҙ 5лҘј л„ҳм–ҙк°Җ лі‘л ¬мІҳлҰ¬лҘј н•ҳлҠ” кІғмқ„ ліј мҲҳ мһҲм—ҲлӢӨ. к·ёл ҮлӢӨл©ҙ 비мҡ©мқҙ 5к°Җ л„ҳм–ҙк°ҖкІҢ ioлҸ„ к°ҖмӨ‘м№ҳлҘј мЈјл©ҙ лі‘л ¬мІҳлҰ¬лҘј н•ҳм§Җ м•Ҡмқ„к№Ңн•ҳлҠ” мғқк°Ғмқ„ н•ҙлҙӨлӢӨ. sql server 2008 r2м—җм„ң DBCC SETIOWEIGHT(10000); кіј к°ҷмқҙ ioм—җ к°ҖмӨ‘м№ҳлҘј мЈјм–ҙлҙӨмңјлӮҳ лі‘л ¬мІҳлҰ¬ мӢӨн–ү кі„нҡҚмқҙ л§Ңл“Өм–ҙм§Җм§Җ м•Ҡм•ҳлӢӨ. мқҙл•Ң cpu к°ҖмӨ‘м№ҳлҠ” 1мқҙм—ҲлӢӨ. н•ҳм§Җл§Ң DBCC SETCPUWEIGHT(10); кіј к°ҷмқҙ к°ҖмӨ‘м№ҳлҘј мЈјлӢҲ лі‘л ¬мІҳлҰ¬ мӢӨн–үкі„нҡҚмқ„ м„ёмҡ°лҚ”лқј. ioмҷҖ cpu к°ҖмӨ‘м№ҳлҘј м Ғм ҲнһҲ мЈјм–ҙ мӢӨн–үкі„нҡҚмқ„ мң лҸ„мӢңнӮӨл©ҙ к°•м ңлЎң лі‘л ¬мІҳлҰ¬ н• мҲҳ мһҲмқҢмқ„ м•Ң мҲҳ мһҲлӢӨ.
DBCC FREEPROCCACHE DBCC SETCPUWEIGHT(10); DBCC SETIOWEIGHT(10000); go select count(*) from master.dbo.spt_values option (recompile, querytraceon 8649) go DBCC SETCPUWEIGHT(1); -- Default CPU weight DBCC SETIOWEIGHT(1); go
лӯҗ...TRACEON н–ҲлҚҳкұ° TRACEOFF н•ҳмһҗ.
DBCC TRACEOFF (3604);
DBCC лӘ…л №мқ„ кі„мҶҚ мӮ¬мҡ©н• мҲҳ м—ҶмңјлӢҲ, play_guide(кі„нҡҚм§Җм№Ё)лҘј мқҙмҡ©н•ҳл©ҙ лҗҳкІғлӢӨ. лҳҗлҠ” лӢӨмқҢкіј к°ҷмқҙ лі‘л ¬ мӢӨн–ү кі„нҡҚмқ„ xmlлЎң л– м„ң мӢӨн–үн•ҳл©ҙ лҗҳкІғлӢӨ.
select count(*) from master.dbo.spt_values option (use plan N'<?xml version="1.0" encoding="utf-16"?> ... ... ... --мҶҢмҠӨк°Җ кёём–ҙм„ң м•„лһҳмқҳ source_01.txtлЎң мІЁл¶Җн•ҳмҳҖлӢӨ.source_01.txt (мғҲм°Ҫм—җм„ң м—ҙлҰј)
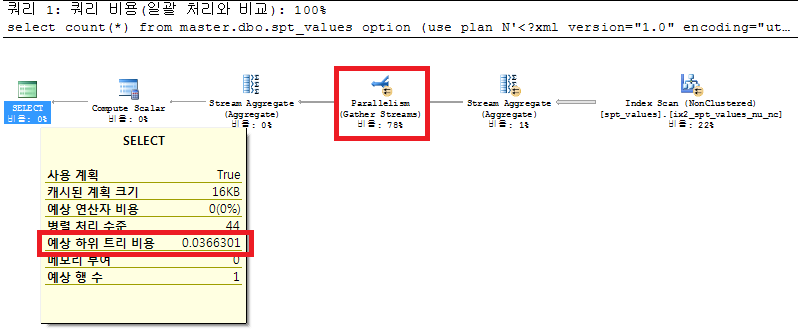
нҠ№мқҙн•ң м җмқҖ мҳҲмғҒн•ҳмң„нҠёлҰ¬ 비мҡ©мқҙ 5лҘј л„ҳм§Җ м•Ҡм•ҳлӢӨлҠ” кІғмқҙлӢӨ. м–ҙм°Ңлҗҳм—Ҳкұҙ sql serverлҠ” нһҢнҠёлЎң мӨҖ мӢӨн–үкі„нҡҚмқ„ к·ёлҢҖлЎң мӮ¬мҡ©н•ң кІғмқҙлӢӨ. лӯҗ.. к°ҖлҒ”м”© м“ёл§Ңн• лқјлӮҳ?
[edit]
5 нҢҢнӢ°м…ҳ 압축 #
set nocount on
set statistics io off
declare
@bdt char(8)
, @edt char(8)
, @p int
, @sql varchar(4000)
set @bdt = '20110928'
while (@bdt <= '20300301')
begin
set @edt = convert(char(8), dateadd(dd, 1, @bdt), 112)
set @p = $partition.нҢҢнӢ°м…ҳн•ЁмҲҳ(@bdt)
set @sql = '
alter table н…Ңмқҙлё”лӘ…
rebuild partition = ' + convert(varchar, @p) + '
with (data_compression = page)'
exec (@sql)
print @sql
--print @bdt + ', ' + @edt
set @bdt = @edt
end
[edit]
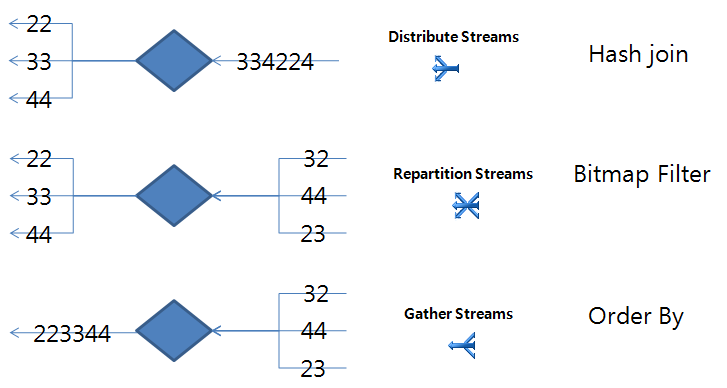
6 Distribute, Repartition, Gather Stream #
sql server мҳөнӢ°л§Ҳмқҙм ҖлҠ” serial vs parallel 비мҡ©мқ„ 비көҗн•ҙм„ң л‘ҳ мӨ‘м—җ мһ‘мқҖ кІғмқ„ м„ нғқн•ңлӢӨкі н•ңлӢӨ.
[edit]
7 кІ°лЎ #
2005ліҙлӢӨ лі‘л ¬мІҳлҰ¬к°Җ мўӢм•„мЎҢлӢӨ. м•Ңкі лҰ¬мҰҳ(мІҳлҰ¬л°©мӢқ)мқҙ мўӢ아진кұ°м§Җ мӢӨм ң нҷҳкІҪм—җм„ң мўӢм•„мЎҢлӢӨкі лҠ” ліј мҲҳ м—ҶлӢӨ. к·ёлҰјмқ„ ліҙл©ҙ м•ҢкІ м§Җл§Ң л…јлҰ¬м Ғ мқҪкё° мҲҳк°Җ 2008 лІ„м „мқҙ лҚ” л§ҺмқҖ л¶Җ분мқҙ мһҲлӢӨ. мқҙм ңк№Ңм§Җ I/O Baseмқҳ м„ұлҠҘнҠңлӢқ кё°мӨҖмқҙ л°”лҖҢм—ҲлӢӨкі ліј мҲҳлҸ„ мһҲлҠ” кІғмқҙлӢӨ. лі‘л ¬мІҳлҰ¬лҠ” н•ҳл“ңмӣЁм–ҙ мһҗмӣҗмқ„ мөңлҢҖн•ң л§Һмқҙ м“°кі мөңлҢҖн•ң нҡЁмңЁм ҒмңјлЎң мІҳлҰ¬н•ҳкё° мң„н•ң мІҳлҰ¬л°©лІ•мқҙлҜҖлЎң I/Oм—җ л„Ҳл¬ҙ 집착н•ҳм§ҖлҠ” л§җм•„м•ј н• кІғмқҙлӢӨ. CPU, RAM, Disk м–ҙлҠҗ н•ң кіімқҙлқјлҸ„ лі‘лӘ©нҳ„мғҒмқҙ л°ңмғқн•ҳл©ҙ мӢңмҠӨн…ңмқҖ м „мІҙм ҒмңјлЎң лҠҗл Ө진лӢӨлҠ” 진лҰ¬лҠ” м—¬м „нһҲ мң нҡЁн•ҳлӢӨ.
![[http]](/moniwiki/imgs/http.png)

п»ҝ