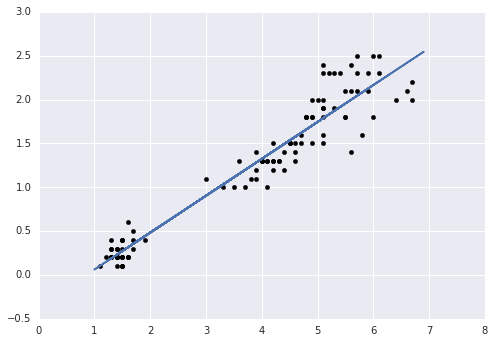
#iris лН∞мЭінД∞мДЄнКЄ лІМлУ§кЄ∞ import numpy as np import pandas as pd from sklearn.datasets import load_iris iris = load_iris() iris.data iris.feature_names iris.target iris.target_names iris_df = pd.DataFrame(iris.data, columns=iris.feature_names) iris_df["target"] = iris.target iris_df["target_names"] = iris.target_names[iris.target] iris_df[:5] #нЫИ놮мДЄнКЄ, нЕМмК§нКЄмДЄнКЄ лВШлИДкЄ∞ from sklearn.model_selection import train_test_split train_set, test_set = train_test_split(iris_df, test_size = 0.3) train_set.shape test_set.shape #мД†нШХ нЪМкЈА(мµЬмЖМм†Ьк≥±) from sklearn.linear_model import LinearRegression as lm model = lm().fit(X=train_set.ix[:, [2]], y=train_set.ix[:, [3]]) print(model.coef_) print(model.intercept_) #plot import matplotlib.pyplot as plt plt.scatter(train_set.ix[:, [2]], train_set.ix[:, [3]], color='black') plt.plot(test_set.ix[:, [2]], model.predict(test_set.ix[:, [2]]))