[edit]
1 Binary Classification #
#iris лҚ°мқҙн„°м„ёнҠё л§Ңл“Өкё°
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris.data
iris.feature_names
iris.target
iris.target_names
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
iris_df["target"] = iris.target
iris_df["target_names"] = iris.target_names[iris.target]
#binary classificationмқҙлҜҖлЎң setosaмқҙл©ҙ 1 м•„лӢҲл©ҙ 0мңјлЎң 분лҘҳн•ҳмһҗ.
from pandasql import sqldf
pysqldf = lambda q: sqldf(q, globals())
iris_df["is_setosa"] = pysqldf("""
select *, case when target_names = 'setosa' then 1 else 0 end is_setosa
from iris_df
""")["is_setosa"]
iris_df[:5]
#нӣҲл Ём„ёнҠё, н…ҢмҠӨнҠём„ёнҠё лӮҳлҲ„кё°
from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(iris_df, test_size = 0.5)
train_set.shape
test_set.shape
#scatter plot
import seaborn as sns
sns.pairplot(x_vars=["sepal length (cm)"], y_vars=["petal length (cm)"], data=train_set, hue="target_names", size=5)
#Logistic Classification
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(C=10) #Cк°’мқ„ мЎ°м •н•ҳм—¬ over fittingмқ„ л§үмһҗ. Cк°’мқ„ лҶ’мқҙл©ҙ лҶ’мқјмҲҳлЎқ over fitting лҗ кІғмһ„
#нӣҲл Ё
model.fit(X=train_set[["sepal length (cm)", "petal length (cm)"]], y=train_set[["is_setosa"]])
#н…ҢмҠӨнҠё
pred = model.predict(X=test_set[["sepal length (cm)", "petal length (cm)"]])
# consusion matrixлҠ” лӢӨмқҢмқ„ м°ёкі
# https://uberpython.wordpress.com/2012/01/01/precision-recall-sensitivity-and-specificity/
# https://stackoverflow.com/questions/31324218/scikit-learn-how-to-obtain-true-positive-true-negative-false-positive-and-fal
from pandas_ml import ConfusionMatrix
cm = ConfusionMatrix(test_set.is_setosa.values, pred)
cm.print_stats()
#м җмҲҳ
print(model.score(X=train_set[["sepal length (cm)", "petal length (cm)"]], y=train_set[["is_setosa"]]))
print(model.score(X=test_set[["sepal length (cm)", "petal length (cm)"]], y=test_set[["is_setosa"]]))
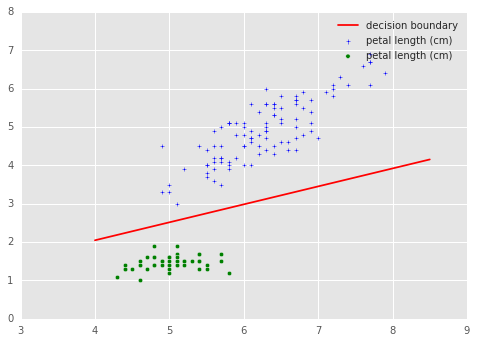
#plot
from matplotlib import pyplot as plt
fig = plt.figure()
plt.scatter(iris_df[iris_df.is_setosa == 0]["sepal length (cm)"], iris_df[iris_df.is_setosa == 0]["petal length (cm)"], marker='+')
plt.scatter(iris_df[iris_df.is_setosa == 1]["sepal length (cm)"], iris_df[iris_df.is_setosa == 1]["petal length (cm)"], c= 'green', marker='o')
coef = model.coef_
intercept = model.intercept_
ex1 = np.linspace(4, 8.5)
ex2 = -(coef[:, 0] * ex1 + intercept) / coef[:,1]
plt.plot(ex1, ex2, color='r', label='decision boundary');
plt.legend();
кІ°кіј