мҳҲм ң
#data
val <- c(462604.2114,724545.9975,677961.1773,556621.1925,572068.4823,550408.0245,442748.9577,463050.285,485241.4509,406399.9335,394768.1661,474606.3792,408121.4988,254290.8273,234755.1933,201690.9834,
175243.2,171106.0665,228024.2613,199481.5251,141505.8969,148199.988,138756.7692,140078.0631,146512.2765,183688.7274,169084.7955,103705.1421,107350.3998,106554.8355,99301.161,105367.9611,148672.9455,
135343.5096,73087.3671,75604.4967,69973.8132,66367.3878,72191.2371,98143.1619,88506.7773,59722.086,59705.1591,54111.3165,49504.2126,50762.7774,68940.2766,67763.3592,50401.3383,50509.8696,51749.5161,
56774.814,56875.3797,65898.4131,58036.3659,45687.6945,44862.2592,41548.5696,37896.342,39405.8232,54220.8435,50035.9164,36221.5746,35067.5583,33099.0594,41550.561,33312.1392,42200.7531,36982.2894,26394.0156,
25939.9764,24163.6476,23641.9008,25495.8942,35859.1398,31292.8596,20783.2461,21233.3025,20770.302,20744.4138,19822.3956,31262.9886,28102.6368,17650.7739,17666.7051,17097.1647,16079.5593,17644.7997,26329.2951,
22879.1946,14800.0848,15000.2205,15227.2401,19307.6187,20345.1381,27219.4509,22791.573,14828.9601,26459.7318,65060.0337)
seq <- 1:length(val)
tmp <- data.frame(seq, val)
#log-normal function
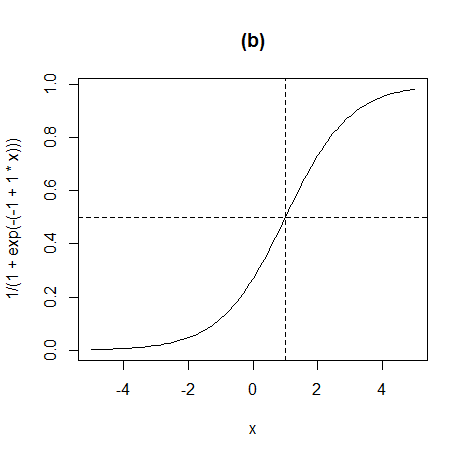
fun <- function(x, mu, sd){
a <- 1/(x * sqrt(2*pi*sd))
b <- (log(x)-mu)^2 * -1
c <- 2 * sd^2
return (a * exp(b/c))
}
#fitting
library("minpack.lm")
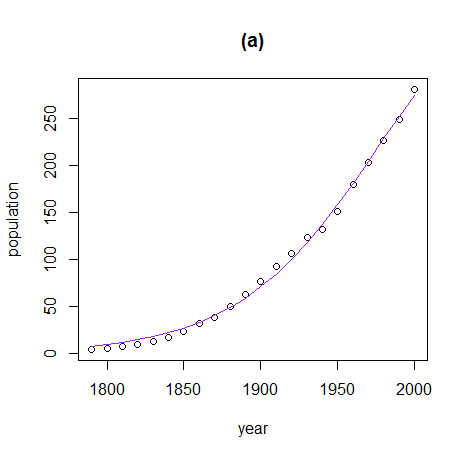
fit <- nlsLM(val ~ a * fun(seq, b, c) + d,
start = list(a=1, b=0.01, c=100, d=1),
control = nls.lm.control(maxiter = 1000),
trace = TRUE,
data=tmp)
#plotting
r <- sort(unique(tmp$seq))
xlim <- c(1,max(r))
ylim <- c(0, max(tmp$val) + max(tmp$val) * 0.3)
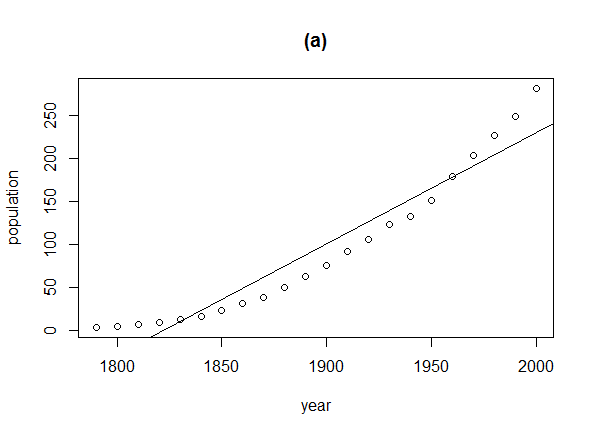
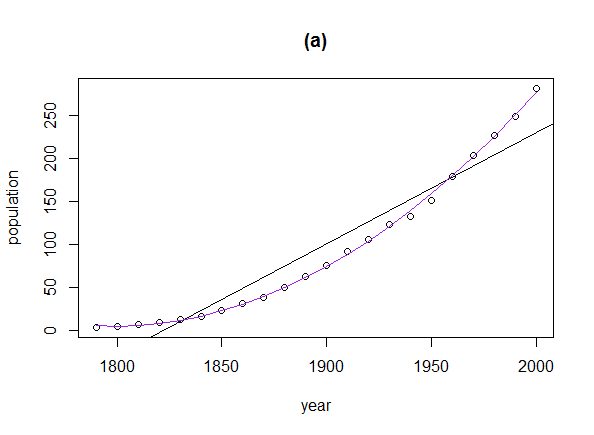
plot(tmp$seq, tmp$val, cex=0.1, pch=19, xlim=xlim, ylim=ylim)
lines(r, predict(fit, data.frame(seq=r)), col="red")


![[http]](/moniwiki/imgs/http.png)