[edit]
1 к°ңмҡ” #
DBSCAN(min_sample, eps)мқҖ кө°м§‘ м•Ңкі лҰ¬мҰҳмқҙкі , л§Өк°ңліҖмҲҳк°Җ 2к°ңлӢӨ.
- min_sample
- eps
- лһңлҚӨмңјлЎң лҚ°мқҙн„° нҸ¬мқёнҠёлҘј лҪ‘кі , лҚ°мқҙн„° нҸ¬мқёнҠём—җм„ң eps(epsilon)мқҳ кұ°лҰ¬(кё°ліёк°’мқҖ мң нҒҙлҰ¬л””м•Ҳ кұ°лҰ¬)м•Ҳм—җ лҚ°мқҙн„° нҸ¬мқёнҠёлҘј м°ҫлҠ”лӢӨ.
- л§Ңм•Ҫ м°ҫмқҖ нҸ¬мқёнҠёк°Җ min_sampleмҲҳліҙлӢӨ м Ғмңјл©ҙ noiseлЎң мІҳлҰ¬н•ҳкі , min_sampleліҙлӢӨ л§Һмңјл©ҙ мғҲлЎңмҡҙ нҒҙлҹ¬мҠӨн„° л Ҳмқҙлё” н• лӢ№
- мғҲлЎңмҡҙ нҒҙлҹ¬мҠӨн„°м—җ н• лӢ№лҗң нҸ¬мқёнҠёл“Өмқҳ eps кұ°лҰ¬ м•Ҳмқҳ лӘЁл“ мқҙмӣғмқ„ м°ҫм•„м„ң нҒҙлҹ¬мҠӨн„° л Ҳмқҙлё”мқҙ н• лӢ№лҗҳм§Җ м•Ҡм•ҳлӢӨл©ҙ нҳ„мһ¬мқҳ нҒҙлҹ¬мҠӨн„°м—җ нҸ¬н•ЁмӢңнӮЁлӢӨ.
- лҚ” мқҙмғҒ лҚ°мқҙн„° нҸ¬мқёк°Җ м—Ҷмңјл©ҙ нҒҙлҹ¬мҠӨн„° л Ҳмқҙлё”мқҙ н• лӢ№лҗҳм§Җ м•ҠмқҖ лҚ°мқҙн„° нҸ¬мқёнҠёл“Өм—җ лҢҖн•ҙ 1~3 л°ҳліө
- k-means л§ҲлғҘ kлҘј кІ°м •н•ҳм§Җ м•Ҡм•„лҸ„ лҗңлӢӨ.
- л§Өк°ңліҖмҲҳ(min_sample, eps)лҘј мһҳ мЎ°м Ҳн•ҳл©ҙ лӢӨлҘё нҒҙлҹ¬мҠӨн„°л§Ғ л°©лІ•ліҙлӢӨ мҡ°мҲҳн•ң кІ°кіјлҘј м–»мқ„ мҲҳ мһҲлӢӨ.
- мўҖ лҠҗлҰ¬лӢӨ.
- нҒҙлҹ¬мҠӨн„°к°Җ л§Һмқҙ мғқкёё мҲҳ мһҲлӢӨ. --> eps, min_sampleмқ„ мһҳ мЎ°м Ҳн•ҙм•ј н•ңлӢӨ.
[edit]
2 мҳҲм ң #
#two_moon лҚ°мқҙн„° м…Ӣ
from sklearn.datasets import make_moons
import pandas as pd
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
df = pd.DataFrame(X, columns=["x", "y"])
df["group"] = y
df[:5]
#import matplotlib.pyplot as plt
#plt.scatter(x=df.x, y=df.y, c=df.group)
#<scatter plot>: м—¬кё°л¶Җн„°
import matplotlib.pyplot as plt
plt.scatter(x=df.x, y=df.y, c=df.group)
fig, ax = plt.subplots()
colors = {1:'red', 0:'blue'}
grouped = df.groupby('group')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
plt.show()
#</scatter plot>: м—¬кё°к№Ңм§Җ н•ңлІҲм—җ мӢӨн–ү
#н‘ңмӨҖнҷ”(нҸүк· =0, 분мӮ°=1)
from sklearn.preprocessing import StandardScaler
scale = StandardScaler()
scale.fit(df[["x", "y"]])
scaled_X = scale.transform(df[["x", "y"]])
df["scaled_x"] = scaled_X[:,0]
df["scaled_y"] = scaled_X[:,1]
#DBSCAN
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=5) #кё°ліёк°’мқҙлӢӨ.
cluster = dbscan.fit_predict(scaled_X)
df["cluster"] = cluster
#clustering кІ°кіј нҷ•мқё
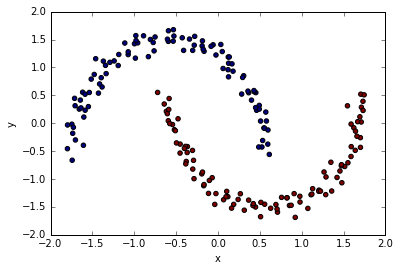
plt.scatter(x=df.scaled_x, y=df.scaled_y, c=df.cluster)
plt.xlabel("x")
plt.ylabel("y")
кІ°кіј
[edit]
3 м°ёкі #
- https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/ --> DBSCANмқҙ м–ҙл–»кІҢ лҸҷмһ‘н•ҳлҠ”м§Җ м• лӢҲл§Өмқҙм…ҳмңјлЎң ліј мҲҳ мһҲлӢӨ.
п»ҝ