![[-]](/moniwiki/imgs/plugin/arrup.png "[-]")
![[+]](/moniwiki/imgs/plugin/arrdown.png "[+]")
[edit]
1 개요 #
DBSCAN(min_sample, eps)은 군집 알고리즘이고, 매개변수가 2개다.
- min_sample
- eps
- 랜덤으로 데이터 포인트를 뽑고, 데이터 포인트에서 eps(epsilon)의 거리(기본값은 유클리디안 거리)안에 데이터 포인트를 찾는다.
- 만약 찾은 포인트가 min_sample수보다 적으면 noise로 처리하고, min_sample보다 많으면 새로운 클러스터 레이블 할당
- 새로운 클러스터에 할당된 포인트들의 eps 거리 안의 모든 이웃을 찾아서 클러스터 레이블이 할당되지 않았다면 현재의 클러스터에 포함시킨다.
- 더 이상 데이터 포인가 없으면 클러스터 레이블이 할당되지 않은 데이터 포인트들에 대해 1~3 반복
- k-means 마냥 k를 결정하지 않아도 된다.
- 매개변수(min_sample, eps)를 잘 조절하면 다른 클러스터링 방법보다 우수한 결과를 얻을 수 있다.
- 좀 느리다.
- 클러스터가 많이 생길 수 있다. --> eps, min_sample을 잘 조절해야 한다.
[edit]
2 예제 #
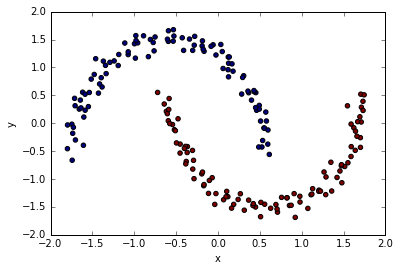
#two_moon 데이터 셋
from sklearn.datasets import make_moons
import pandas as pd
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
df = pd.DataFrame(X, columns=["x", "y"])
df["group"] = y
df[:5]
#import matplotlib.pyplot as plt
#plt.scatter(x=df.x, y=df.y, c=df.group)
#<scatter plot>: 여기부터
import matplotlib.pyplot as plt
plt.scatter(x=df.x, y=df.y, c=df.group)
fig, ax = plt.subplots()
colors = {1:'red', 0:'blue'}
grouped = df.groupby('group')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
plt.show()
#</scatter plot>: 여기까지 한번에 실행
#표준화(평균=0, 분산=1)
from sklearn.preprocessing import StandardScaler
scale = StandardScaler()
scale.fit(df[["x", "y"]])
scaled_X = scale.transform(df[["x", "y"]])
df["scaled_x"] = scaled_X[:,0]
df["scaled_y"] = scaled_X[:,1]
#DBSCAN
from sklearn.cluster import DBSCAN
dbscan = DBSCAN(eps=0.5, min_samples=5) #기본값이다.
cluster = dbscan.fit_predict(scaled_X)
df["cluster"] = cluster
#clustering 결과 확인
plt.scatter(x=df.scaled_x, y=df.scaled_y, c=df.cluster)
plt.xlabel("x")
plt.ylabel("y")
결과
[edit]
3 참고 #
- https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/ --> DBSCAN이 어떻게 동작하는지 애니매이션으로 볼 수 있다.